Preprocessing of Batches: Bronchial_brushings_Batch7
Quality Control: Removing ambient RNA, low lib reads, high mito content and doublets
George Howitt, Gunjan Dixit and Jovana Maksimovic
July 03, 2024
Last updated: 2024-07-03
Checks: 6 1
Knit directory: paed-airway-allTissues/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown is untracked by Git. To know which version of the R
Markdown file created these results, you’ll want to first commit it to
the Git repo. If you’re still working on the analysis, you can ignore
this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230811) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 75b471c. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.DS_Store
Ignored: data/.DS_Store
Ignored: data/RDS/
Ignored: output/.DS_Store
Ignored: output/CSV/.DS_Store
Ignored: output/G000231_Neeland_batch1/
Ignored: output/G000231_Neeland_batch2_1/
Ignored: output/G000231_Neeland_batch2_2/
Ignored: output/G000231_Neeland_batch3/
Ignored: output/G000231_Neeland_batch4/
Ignored: output/G000231_Neeland_batch5/
Ignored: output/G000231_Neeland_batch9_1/
Ignored: output/RDS/
Ignored: output/plots/
Untracked files:
Untracked: analysis/03_Batch_Integration.Rmd
Untracked: analysis/Age_proportions.Rmd
Untracked: analysis/Age_proportions_AllBatches.Rmd
Untracked: analysis/Batch_Integration_&_Downstream_analysis.Rmd
Untracked: analysis/Batch_correction_&_Downstream.Rmd
Untracked: analysis/Cell_cycle_regression.Rmd
Untracked: analysis/Preprocessing_Batch1_Nasal_brushings.Rmd
Untracked: analysis/Preprocessing_Batch2_Tonsils.Rmd
Untracked: analysis/Preprocessing_Batch3_Adenoids.Rmd
Untracked: analysis/Preprocessing_Batch4_Bronchial_brushings.Rmd
Untracked: analysis/Preprocessing_Batch5_Nasal_brushings.Rmd
Untracked: analysis/Preprocessing_Batch6_BAL.Rmd
Untracked: analysis/Preprocessing_Batch7_Bronchial_brushings.Rmd
Untracked: analysis/Preprocessing_Batch8_Adenoids.Rmd
Untracked: analysis/Preprocessing_Batch9_Tonsils.Rmd
Untracked: analysis/cell_cycle_regression.R
Untracked: analysis/test.Rmd
Untracked: analysis/testing_age_all.Rmd
Untracked: data/Cell_labels_Mel/
Untracked: data/Hs.c2.cp.reactome.v7.1.entrez.rds
Untracked: data/Raw_feature_bc_matrix/
Untracked: data/celltypes_Mel_GD_v3.xlsx
Untracked: data/celltypes_Mel_GD_v4_no_dups.xlsx
Untracked: data/celltypes_Mel_modified.xlsx
Untracked: data/celltypes_Mel_v2.csv
Untracked: data/celltypes_Mel_v2.xlsx
Untracked: data/celltypes_Mel_v2_MN.xlsx
Untracked: data/celltypes_for_mel_MN.xlsx
Untracked: data/earlyAIR_sample_sheets_combined.xlsx
Untracked: output/CSV/BAL_Marker_genes_Reclustered_Tcell_population.RNA_snn_res.0.4/
Untracked: output/CSV/Bronchial_brushings_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/
Untracked: output/CSV/Bronchial_brushings_Marker_genes_Reclustered_Tcell_population.RNA_snn_res.0.4/
Untracked: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Tcell_population.RNA_snn_res.0.4/
Untracked: stacked_barplot.png
Untracked: stacked_barplot_donor_id.png
Unstaged changes:
Deleted: 02_QC_exploratoryPlots.Rmd
Deleted: 02_QC_exploratoryPlots.html
Modified: analysis/00_AllBatches_overview.Rmd
Modified: analysis/01_QC_emptyDrops.Rmd
Modified: analysis/02_QC_exploratoryPlots.Rmd
Modified: analysis/Age_modeling.Rmd
Modified: analysis/AllBatches_QCExploratory.Rmd
Modified: analysis/BAL.Rmd
Modified: analysis/Bronchial_brushings.Rmd
Modified: analysis/Nasal_brushings.Rmd
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c0.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c1.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c10.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c11.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c12.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c13.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c14.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c15.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c16.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c17.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c2.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c3.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c4.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c5.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c6.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c7.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c8.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c9.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c0.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c1.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c10.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c11.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c12.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c13.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c14.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c15.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c16.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c17.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c2.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c3.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c4.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c5.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c6.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c7.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c8.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c9.csv
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown
(analysis/Preprocessing_Batch7_Bronchial_brushings.Rmd) and
HTML (docs/Preprocessing_Batch7_Bronchial_brushings.html)
files. If you’ve configured a remote Git repository (see
?wflow_git_remote), click on the hyperlinks in the table
below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | bd5ec04 | Gunjan Dixit | 2024-05-03 | Modified index |
Introduction
This RMarkdown performs quality control for the earlyAIR batch- Bronchial_brushings- Batch7
The steps are: * Load CellRanger counts * Run decontX to determine contamination and correct * Filter cells with low library size and high mitochondrial counts * Identify doublets * Scale, Normalize, Run PCA, UMAP, Azimuth annotation before/after doublet removal * Save Seurat object
suppressPackageStartupMessages({
library(BiocStyle)
library(BiocParallel)
library(tidyverse)
library(here)
library(glue)
library(scran)
library(scater)
library(scuttle)
library(janitor)
library(cowplot)
library(patchwork)
library(scales)
library(Homo.sapiens)
library(msigdbr)
library(EnsDb.Hsapiens.v86)
library(ensembldb)
library(readr)
library(Seurat)
library(celda)
library(decontX)
library(Azimuth)
library(Matrix)
library(scDblFinder)
library(scMerge)
library(googlesheets4)
library(lubridate)
library(ggstats)
})
set.seed(42)Get Batch_info
batch_path <- here("output/RDS/AllBatches_filtered_SCEs/G000231_batch7_Bronchial_brushings.CellRanger_filtered.SCE.rds")
batch_info <- str_match(basename(batch_path), "^(G\\d+_batch\\d+)_([A-Za-z_]+)\\.CellRanger_filtered\\.SCE\\.rds$")
batch_name <- batch_info[, 2]
tissue <- batch_info[, 3]sce <- readRDS(batch_path)
sce$tissue <- tissue
sce$batch_name <- batch_name
sceclass: SingleCellExperiment
dim: 18082 30932
metadata(0):
assays(2): counts logcounts
rownames(18082): SAMD11 NOC2L ... MT-ND6 MT-CYB
rowData names(0):
colnames(30932): AAACGTTCAACAGGCTACTTTAGG-1 AAACGTTCATTAGCGAACTTTAGG-1
... TTTGTGAGTCAAGCTTATTCGGTT-1 TTTGTGAGTCCCTCTGATTCGGTT-1
colData names(7): orig.ident nCount_RNA ... tissue batch_name
reducedDimNames(0):
mainExpName: RNA
altExpNames(0):CellRanger calls
Filter cells with zero counts across all genes
sce <- sce[rowSums(counts(sce)) > 0, ]
sceclass: SingleCellExperiment
dim: 15215 30932
metadata(0):
assays(2): counts logcounts
rownames(15215): SAMD11 NOC2L ... MT-ND6 MT-CYB
rowData names(0):
colnames(30932): AAACGTTCAACAGGCTACTTTAGG-1 AAACGTTCATTAGCGAACTTTAGG-1
... TTTGTGAGTCAAGCTTATTCGGTT-1 TTTGTGAGTCCCTCTGATTCGGTT-1
colData names(7): orig.ident nCount_RNA ... tissue batch_name
reducedDimNames(0):
mainExpName: RNA
altExpNames(0):cell_counts <- c()
cell_counts["Post CellRanger Filtering"] <- ncol(sce)Add Barcode metadata
The first 17 characters of the barcodes are the GEM barcode and the last 9 characters are the sample barcode. Create a metadata feature for each of these.
sce$Barcode <- unname(substring(colnames(sce), first = 1, last = 26))
sce$GEM_barcode <- substring(sce$Barcode, first = 1, last = 17)
sce$sample_barcode <- substring(sce$Barcode, first = 18, last = 26)Pre-processing
DecontX
Correcting for ambient RNA with decontX, actually replacing the raw counts with the decontX counts. These can be forced to be integers rather than doubles later if necessary, but so far it doesn’t seem to be an issue.
sce <- decontX(sce)--------------------------------------------------Starting DecontX--------------------------------------------------Wed Jul 3 15:44:09 2024 .. Analyzing all cellsWed Jul 3 15:44:09 2024 .... Generating UMAP and estimating cell typesFound more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'Also defined by 'spam'Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'Also defined by 'spam'Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'Also defined by 'spam'Wed Jul 3 15:45:14 2024 .... Estimating contaminationWed Jul 3 15:45:16 2024 ...... Completed iteration: 10 | converge: 0.03809Wed Jul 3 15:45:17 2024 ...... Completed iteration: 20 | converge: 0.01821Wed Jul 3 15:45:18 2024 ...... Completed iteration: 30 | converge: 0.01316Wed Jul 3 15:45:19 2024 ...... Completed iteration: 40 | converge: 0.007534Wed Jul 3 15:45:20 2024 ...... Completed iteration: 50 | converge: 0.004167Wed Jul 3 15:45:21 2024 ...... Completed iteration: 60 | converge: 0.003106Wed Jul 3 15:45:22 2024 ...... Completed iteration: 70 | converge: 0.002468Wed Jul 3 15:45:23 2024 ...... Completed iteration: 80 | converge: 0.002154Wed Jul 3 15:45:24 2024 ...... Completed iteration: 90 | converge: 0.00182Wed Jul 3 15:45:25 2024 ...... Completed iteration: 100 | converge: 0.001566Wed Jul 3 15:45:26 2024 ...... Completed iteration: 110 | converge: 0.001405Wed Jul 3 15:45:27 2024 ...... Completed iteration: 120 | converge: 0.001181Wed Jul 3 15:45:29 2024 ...... Completed iteration: 130 | converge: 0.0009977Wed Jul 3 15:45:29 2024 .. Calculating final decontaminated matrix--------------------------------------------------Completed DecontX. Total time: 1.348419 mins--------------------------------------------------assay(sce, "raw_counts") <- counts(sce)
counts(sce) <- decontXcounts(sce)Filter on library size filter after running decontX
sce <- addPerCellQCMetrics(sce)
sum(sce$sum < 250)[1] 952sce <- sce[, sce$sum >= 250]
cell_counts["Post low-lib Filtering"] <- ncol(sce)Mitochondrial filtering
Filtering out cells with high mitochondrial content.
is.mito <- grepl(pattern = "^MT", rownames(sce))
sce <- addPerCellQCMetrics(sce, subsets = list(mito = is.mito))
mito_outliers <- isOutlier(sce$subsets_mito_percent, type = "higher")
sum(mito_outliers)[1] 4494sce <- sce[, !mito_outliers]
cell_counts["Post Mito Filtering"] <- ncol(sce)Multiplet filtering
We know that there will be some unidentified multiplets in our data, as higher-occupancy GEMs have many ways to include multiple cells from the same samples. Still working on a way to estimate the number of these but the existing doublet-finding tools work ok. Using scDblFinder as that seemed to have the best effect on the GEM-level counts.
sce <- logNormCounts(sce) %>%
runPCA() %>%
runUMAP()Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'Also defined by 'spam'Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'Also defined by 'spam'Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'Also defined by 'spam'Run scDblFinder
bp <- MulticoreParam(8, RNGseed=56213)
sce <- scDblFinder(sce, clusters = T,
BPPARAM=bp)Clustering cells...17 clustersCreating ~20389 artificial doublets...Dimensional reductionEvaluating kNN...Training model...iter=0, 3186 cells excluded from training.iter=1, 3234 cells excluded from training.iter=2, 3201 cells excluded from training.Threshold found:0.3653344 (13.1%) doublets calledtable(sce$scDblFinder.class)
singlet doublet
22142 3344 Make Seurat object
seu <- CreateSeuratObject(counts(sce), meta.data = as.data.frame(colData(sce)))Add GEM metadata to the cell-level objects
seu$cells_per_GEM <- table(seu$GEM_barcode)[seu$GEM_barcode]table(seu$cells_per_GEM)
1 2 3 4
16566 6444 1944 532 Normalization and Azimuth annotation
seu <- NormalizeData(seu, verbose = F) %>%
FindVariableFeatures(nfeatures = 2000, verbose = F) %>%
ScaleData(verbose = F) %>%
RunPCA(dims = 1:30, verbose = F) %>%
RunUMAP(dims = 1:30, verbose = F) options(timeout = max(1000000, getOption("timeout")))
tmp <- RunAzimuth(seu, reference = "lungref") detected inputs from HUMAN with id type Gene.namereference rownames detected HUMAN with id type Gene.nameNormalizing query using reference SCT modelProjecting cell embeddingsFinding query neighborsFinding neighborhoodsFinding anchors Found 7384 anchorsFinding integration vectorsFinding integration vector weightsPredicting cell labels
Predicting cell labels
Predicting cell labels
Predicting cell labels
Predicting cell labels
Predicting cell labels
Integrating dataset 2 with reference datasetFinding integration vectorsIntegrating dataComputing nearest neighborsRunning UMAP projection15:51:58 Read 25486 rows15:51:58 Processing block 1 of 115:51:58 Commencing smooth kNN distance calibration using 1 thread with target n_neighbors = 20
15:51:58 Initializing by weighted average of neighbor coordinates using 1 thread
15:51:58 Commencing optimization for 67 epochs, with 509720 positive edges
15:52:00 Finished
Projecting reference PCA onto query
Finding integration vector weights
Projecting back the query cells into original PCA space
Finding integration vector weights
Computing scores:
Finding neighbors of original query cells
Finding neighbors of transformed query cells
Computing query SNN
Determining bandwidth and computing transition probabilities
Total elapsed time: 9.58829617500305seu@meta.data <- tmp@meta.dataAdd Batch specific meta data
f <- c("https://docs.google.com/spreadsheets/d/1FKo-7MweuFDoKBm8DMFcMOuq0LyK_K6GVNAAo_n-ItE/edit#gid=1882418352")
dat <- bind_rows(lapply(1:10, function(sheet) read_sheet(ss = f, sheet = sheet)))
dat# A tibble: 153 × 13
sample_id donor_id probe_barcode_id sample_oligo expected cell number recov…¹
<chr> <chr> <chr> <chr> <dbl>
1 s001 eAIR004 BC001 CTTTAGG-1 8000
2 s002 eAIR005 BC002 ACGGGAA-1 1789
3 s003 eAIR006 BC003 GTAGGCT-1 8000
4 s004 eAIR007 BC004 TGTTGAC-1 5368
5 s005 eAIR011 BC005 CAGACCT-1 8000
6 s006 eAIR013 BC006 TCCCAAC-1 8000
7 s007 eAIR016 BC007 AGTAGAG-1 8000
8 s008 eAIR017 BC008 GCTGTGA-1 8000
9 s009 eAIR019 BC009 CAGTCTG-1 8000
10 s010 eAIR020 BC010 GTGAGTG-1 8000
# ℹ 143 more rows
# ℹ abbreviated name: ¹`expected cell number recovered`
# ℹ 8 more variables: `sample type` <chr>, patient <chr>, sex <chr>,
# age_years <dbl>, batch <dbl>, viability <dbl>, `second pool` <dbl>,
# run <chr>batch_meta <- dat %>%
dplyr::filter(run == "batch7_1")
batch_meta$donor_id <- gsub("_", "-", batch_meta$donor_id) #For Batch7
seu$sample_id <- sapply(seu$Sample, function(x) batch_meta$sample_id[batch_meta$donor_id == x])
seu$donor_id <- sapply(seu$Sample, function(x) batch_meta$donor_id[batch_meta$donor_id == x])
seu$sex <- sapply(seu$Sample, function(x) batch_meta$sex[batch_meta$donor_id == x])
seu$age_years <- sapply(seu$Sample, function(x) batch_meta$age_years[batch_meta$donor_id == x])Clean up no longer-useful metadata
seu@meta.data <- seu@meta.data %>%
dplyr::select(c(donor_id,sample_id, age_years, sex, nCount_RNA, nFeature_RNA,
Barcode, GEM_barcode, sample_barcode,
tissue, batch_name,
cells_per_GEM,
scDblFinder.class, scDblFinder.score,
predicted.ann_level_1, predicted.ann_level_1.score, predicted.ann_level_2, predicted.ann_level_2.score, predicted.ann_level_3, predicted.ann_level_3.score, predicted.ann_level_4, predicted.ann_level_4.score, predicted.ann_level_5, predicted.ann_level_5.score, predicted.ann_finest_level, predicted.ann_finest_level.score))Save pre-processed objects
out <- here("output",
"RDS", "AllBatches_Azimuth_SEUs",
paste0(batch_name, "_", tissue, ".CellRanger.decontX.mito.filter.Azimuth.SEU.rds"))
saveRDS(seu, file = out)Filter doublets and repeat
seu <- seu[, seu$scDblFinder.class == "singlet"]
cell_counts["Post Doublet Filtering"] <- ncol(sce)Normalization and Azimuth annotation
seu <- NormalizeData(seu, verbose = F) %>%
FindVariableFeatures(nfeatures = 2000, verbose = F) %>%
ScaleData(verbose = F) %>%
RunPCA(dims = 1:30, verbose = F) %>%
RunUMAP(dims = 1:30, verbose = F) Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'Also defined by 'spam'Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'Also defined by 'spam'options(timeout = max(1000000, getOption("timeout")))
tmp <- RunAzimuth(seu, reference = "lungref") detected inputs from HUMAN with id type Gene.namereference rownames detected HUMAN with id type Gene.nameNormalizing query using reference SCT modelProjecting cell embeddingsFinding query neighborsFinding neighborhoodsFinding anchors Found 7062 anchorsFinding integration vectorsFinding integration vector weightsPredicting cell labels
Predicting cell labels
Predicting cell labels
Predicting cell labels
Predicting cell labels
Predicting cell labels
Integrating dataset 2 with reference datasetFinding integration vectorsIntegrating dataComputing nearest neighborsRunning UMAP projection15:57:26 Read 22142 rows15:57:26 Processing block 1 of 115:57:26 Commencing smooth kNN distance calibration using 1 thread with target n_neighbors = 20
15:57:26 Initializing by weighted average of neighbor coordinates using 1 thread
15:57:26 Commencing optimization for 67 epochs, with 442840 positive edges
15:57:28 Finished
Projecting reference PCA onto query
Finding integration vector weights
Projecting back the query cells into original PCA space
Finding integration vector weights
Computing scores:
Finding neighbors of original query cells
Finding neighbors of transformed query cells
Computing query SNN
Determining bandwidth and computing transition probabilities
Total elapsed time: 8.5740180015564seu@meta.data <- tmp@meta.datathis figure shows number of cells eliminated at each filtering stage-
counts_df <- data.frame(
Stage = factor(names(cell_counts), levels = c("Post CellRanger Filtering", "Post low-lib Filtering","Post Mito Filtering", "Post Doublet Filtering")),
Cell_Count = as.numeric(cell_counts)
)
a <- ggplot(counts_df, aes(x = Stage, y = Cell_Count, group = 1)) +
geom_line() +
geom_point() +
theme_minimal() +
labs(title = paste0(tissue, " ", batch_name, " :Cell Counts After Each Preprocessing Step"))
#ggsave(a, file=paste0(tissue, " ", batch_name, " :Cells_after_filtering.pdf"), width = 10)
a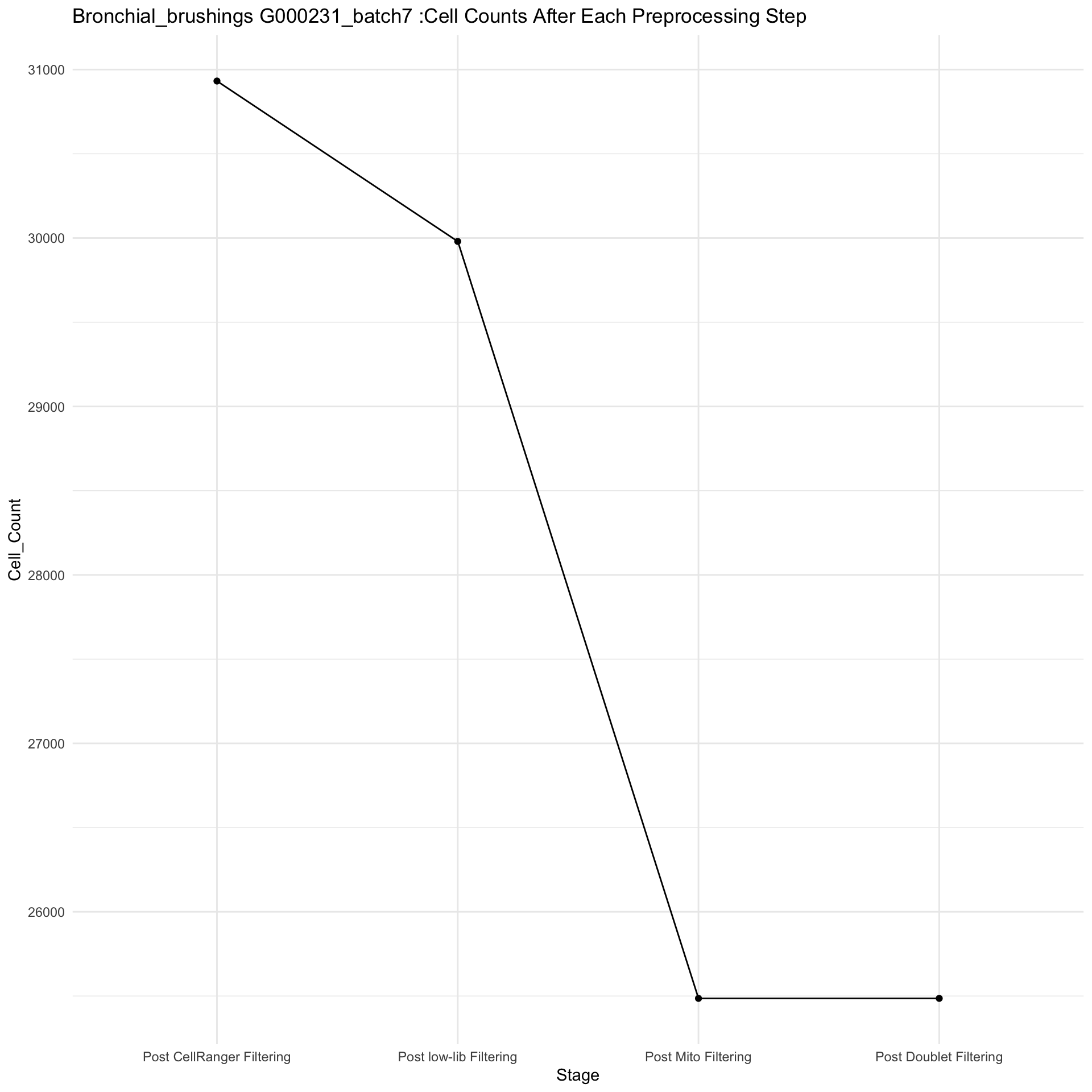
| Version | Author | Date |
|---|---|---|
| bd5ec04 | Gunjan Dixit | 2024-05-03 |
Add harmonized cell-labels
# Function to map cell types to broad cell label
map_to_broad_cell_label <- function(cell_type, broad_cell_labels_df, label_column) {
label <- broad_cell_labels_df[[label_column]][broad_cell_labels_df$`Cell Types` == cell_type]
if (length(label) == 0) {
return("Unknown") # Assign to "Unknown" if not found in mapping
} else {
return(label)
}
}
broad_cell_labels <- readxl::read_excel(here("data/celltypes_Mel_v2_MN.xlsx")) #modified cell types based on Tonsils ref v2
seu$Broad_cell_label_1 <- sapply(seu$predicted.ann_level_4, map_to_broad_cell_label, broad_cell_labels_df = broad_cell_labels, label_column = "Broad cell label level 1")
# Apply mapping to Seurat object for Broad Cell Label 2
seu$Broad_cell_label_2 <- sapply(seu$predicted.ann_level_4, map_to_broad_cell_label, broad_cell_labels_df = broad_cell_labels, label_column = "Broad cell label level 2")
# Apply mapping to Seurat object for Broad Cell Label 3
seu$Broad_cell_label_3 <- sapply(seu$predicted.ann_level_4, map_to_broad_cell_label, broad_cell_labels_df = broad_cell_labels, label_column = "Broad cell label level 3")
table(seu$Broad_cell_label_2 == "Unknown")
FALSE
22142 table(seu$Broad_cell_label_2 == "NA")
FALSE
22142 df <- seu@meta.data %>% dplyr::select(Sample, Broad_cell_label_1, Broad_cell_label_2, Broad_cell_label_3)
write.table(df, file = paste0(batch_name, "_", tissue, "_harmonized_labels_meta.txt"))Save pre-processed objects
out <- here("output",
"RDS", "AllBatches_Azimuth_noDoublets_SEUs",
paste0(batch_name, "_", tissue, ".CellRanger.decontX.mito.doublet.filter.Azimuth.SEU.rds"))
saveRDS(seu, file = out)Session Info
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.3.2 (2023-10-31)
os macOS Sonoma 14.5
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Australia/Melbourne
date 2024-07-03
pandoc 3.1.1 @ /Users/dixitgunjan/Desktop/RStudio.app/Contents/Resources/app/quarto/bin/tools/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
abind 1.4-5 2016-07-21 [1] CRAN (R 4.3.0)
annotate 1.80.0 2023-10-26 [1] Bioconductor
AnnotationDbi * 1.64.1 2023-11-02 [1] Bioconductor
AnnotationFilter * 1.26.0 2023-10-26 [1] Bioconductor
askpass 1.2.0 2023-09-03 [1] CRAN (R 4.3.0)
Azimuth * 0.5.0 2024-02-27 [1] Github (satijalab/azimuth@c3ad1bc)
babelgene 22.9 2022-09-29 [1] CRAN (R 4.3.0)
backports 1.4.1 2021-12-13 [1] CRAN (R 4.3.0)
base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.3.0)
batchelor 1.18.1 2023-12-30 [1] Bioconductor 3.18 (R 4.3.2)
bbmle 1.0.25.1 2023-12-09 [1] CRAN (R 4.3.1)
bdsmatrix 1.3-6 2022-06-03 [1] CRAN (R 4.3.0)
beachmat 2.18.1 2024-02-17 [1] Bioconductor 3.18 (R 4.3.2)
beeswarm 0.4.0 2021-06-01 [1] CRAN (R 4.3.0)
Biobase * 2.62.0 2023-10-26 [1] Bioconductor
BiocFileCache 2.10.1 2023-10-26 [1] Bioconductor
BiocGenerics * 0.48.1 2023-11-02 [1] Bioconductor
BiocIO 1.12.0 2023-10-26 [1] Bioconductor
BiocManager 1.30.22 2023-08-08 [1] CRAN (R 4.3.0)
BiocNeighbors 1.20.2 2024-01-13 [1] Bioconductor 3.18 (R 4.3.2)
BiocParallel * 1.36.0 2023-10-26 [1] Bioconductor
BiocSingular 1.18.0 2023-11-06 [1] Bioconductor
BiocStyle * 2.30.0 2023-10-26 [1] Bioconductor
biomaRt 2.58.2 2024-02-03 [1] Bioconductor 3.18 (R 4.3.2)
Biostrings 2.70.2 2024-01-30 [1] Bioconductor 3.18 (R 4.3.2)
bit 4.0.5 2022-11-15 [1] CRAN (R 4.3.0)
bit64 4.0.5 2020-08-30 [1] CRAN (R 4.3.0)
bitops 1.0-7 2021-04-24 [1] CRAN (R 4.3.0)
blob 1.2.4 2023-03-17 [1] CRAN (R 4.3.0)
bluster 1.12.0 2023-12-19 [1] Bioconductor 3.18 (R 4.3.2)
BSgenome 1.70.2 2024-02-10 [1] Bioconductor 3.18 (R 4.3.2)
BSgenome.Hsapiens.UCSC.hg38 1.4.5 2024-02-27 [1] Bioconductor
bslib 0.6.1 2023-11-28 [1] CRAN (R 4.3.1)
cachem 1.0.8 2023-05-01 [1] CRAN (R 4.3.0)
caTools 1.18.2 2021-03-28 [1] CRAN (R 4.3.0)
celda * 1.18.1 2023-12-23 [1] Bioconductor 3.18 (R 4.3.2)
cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.3.0)
checkmate 2.3.1 2023-12-04 [1] CRAN (R 4.3.1)
cli 3.6.2 2023-12-11 [1] CRAN (R 4.3.1)
cluster 2.1.6 2023-12-01 [1] CRAN (R 4.3.1)
CNEr 1.38.0 2023-10-24 [1] Bioconductor
codetools 0.2-19 2023-02-01 [1] CRAN (R 4.3.2)
colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)
combinat 0.0-8 2012-10-29 [1] CRAN (R 4.3.0)
cowplot * 1.1.3 2024-01-22 [1] CRAN (R 4.3.1)
crayon 1.5.2 2022-09-29 [1] CRAN (R 4.3.0)
curl 5.2.0 2023-12-08 [1] CRAN (R 4.3.1)
cvTools 0.3.2 2012-05-14 [1] CRAN (R 4.3.0)
data.table 1.15.0 2024-01-30 [1] CRAN (R 4.3.1)
DBI 1.2.2 2024-02-16 [1] CRAN (R 4.3.1)
dbplyr 2.4.0 2023-10-26 [1] CRAN (R 4.3.1)
dbscan 1.1-12 2023-11-28 [1] CRAN (R 4.3.1)
decontX * 1.0.0 2023-12-23 [1] Bioconductor 3.18 (R 4.3.2)
DelayedArray 0.28.0 2023-11-06 [1] Bioconductor
DelayedMatrixStats 1.24.0 2023-11-06 [1] Bioconductor
deldir 2.0-2 2023-11-23 [1] CRAN (R 4.3.1)
densEstBayes 1.0-2.2 2023-03-31 [1] CRAN (R 4.3.0)
DEoptimR 1.1-3 2023-10-07 [1] CRAN (R 4.3.1)
digest 0.6.34 2024-01-11 [1] CRAN (R 4.3.1)
DirichletMultinomial 1.44.0 2023-10-26 [1] Bioconductor
distr 2.9.3 2024-01-29 [1] CRAN (R 4.3.1)
doParallel 1.0.17 2022-02-07 [1] CRAN (R 4.3.0)
dotCall64 1.1-1 2023-11-28 [1] CRAN (R 4.3.1)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.3.1)
dqrng 0.3.2 2023-11-29 [1] CRAN (R 4.3.1)
DT 0.32 2024-02-19 [1] CRAN (R 4.3.1)
edgeR 4.0.16 2024-02-20 [1] Bioconductor 3.18 (R 4.3.2)
ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.3.0)
enrichR 3.2 2023-04-14 [1] CRAN (R 4.3.0)
EnsDb.Hsapiens.v86 * 2.99.0 2024-02-27 [1] Bioconductor
ensembldb * 2.26.0 2023-10-26 [1] Bioconductor
evaluate 0.23 2023-11-01 [1] CRAN (R 4.3.1)
fansi 1.0.6 2023-12-08 [1] CRAN (R 4.3.1)
farver 2.1.1 2022-07-06 [1] CRAN (R 4.3.0)
fastDummies 1.7.3 2023-07-06 [1] CRAN (R 4.3.0)
fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)
fastmatch 1.1-4 2023-08-18 [1] CRAN (R 4.3.0)
filelock 1.0.3 2023-12-11 [1] CRAN (R 4.3.1)
fitdistrplus 1.1-11 2023-04-25 [1] CRAN (R 4.3.0)
forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)
foreach 1.5.2 2022-02-02 [1] CRAN (R 4.3.0)
foreign 0.8-86 2023-11-28 [1] CRAN (R 4.3.1)
Formula 1.2-5 2023-02-24 [1] CRAN (R 4.3.0)
fs 1.6.3 2023-07-20 [1] CRAN (R 4.3.0)
future 1.33.1 2023-12-22 [1] CRAN (R 4.3.1)
future.apply 1.11.1 2023-12-21 [1] CRAN (R 4.3.1)
gargle 1.5.2 2023-07-20 [1] CRAN (R 4.3.0)
generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)
GenomeInfoDb * 1.38.6 2024-02-10 [1] Bioconductor 3.18 (R 4.3.2)
GenomeInfoDbData 1.2.11 2024-02-27 [1] Bioconductor
GenomicAlignments 1.38.2 2024-01-20 [1] Bioconductor 3.18 (R 4.3.2)
GenomicFeatures * 1.54.3 2024-02-03 [1] Bioconductor 3.18 (R 4.3.2)
GenomicRanges * 1.54.1 2023-10-30 [1] Bioconductor
ggbeeswarm 0.7.2 2023-04-29 [1] CRAN (R 4.3.0)
ggplot2 * 3.5.0 2024-02-23 [1] CRAN (R 4.3.1)
ggrepel 0.9.5 2024-01-10 [1] CRAN (R 4.3.1)
ggridges 0.5.6 2024-01-23 [1] CRAN (R 4.3.1)
ggstats * 0.5.1 2023-11-21 [1] CRAN (R 4.3.1)
git2r 0.33.0 2023-11-26 [1] CRAN (R 4.3.1)
globals 0.16.2 2022-11-21 [1] CRAN (R 4.3.0)
glue * 1.7.0 2024-01-09 [1] CRAN (R 4.3.1)
GO.db * 3.18.0 2024-02-27 [1] Bioconductor
goftest 1.2-3 2021-10-07 [1] CRAN (R 4.3.0)
googledrive 2.1.1 2023-06-11 [1] CRAN (R 4.3.0)
googlesheets4 * 1.1.1 2023-06-11 [1] CRAN (R 4.3.0)
gplots 3.1.3.1 2024-02-02 [1] CRAN (R 4.3.1)
graph 1.80.0 2023-10-26 [1] Bioconductor
gridExtra 2.3 2017-09-09 [1] CRAN (R 4.3.0)
gtable 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)
gtools 3.9.5 2023-11-20 [1] CRAN (R 4.3.1)
hdf5r 1.3.9 2024-01-14 [1] CRAN (R 4.3.1)
here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)
highr 0.10 2022-12-22 [1] CRAN (R 4.3.0)
Hmisc 5.1-1 2023-09-12 [1] CRAN (R 4.3.0)
hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)
Homo.sapiens * 1.3.1 2024-02-27 [1] Bioconductor
htmlTable 2.4.2 2023-10-29 [1] CRAN (R 4.3.1)
htmltools 0.5.7 2023-11-03 [1] CRAN (R 4.3.1)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.3.1)
httpuv 1.6.14 2024-01-26 [1] CRAN (R 4.3.1)
httr 1.4.7 2023-08-15 [1] CRAN (R 4.3.0)
ica 1.0-3 2022-07-08 [1] CRAN (R 4.3.0)
igraph 2.0.2 2024-02-17 [1] CRAN (R 4.3.1)
inline 0.3.19 2021-05-31 [1] CRAN (R 4.3.0)
IRanges * 2.36.0 2023-10-26 [1] Bioconductor
irlba 2.3.5.1 2022-10-03 [1] CRAN (R 4.3.2)
iterators 1.0.14 2022-02-05 [1] CRAN (R 4.3.0)
janitor * 2.2.0 2023-02-02 [1] CRAN (R 4.3.0)
JASPAR2020 0.99.10 2024-02-27 [1] Bioconductor
jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.3.0)
jsonlite 1.8.8 2023-12-04 [1] CRAN (R 4.3.1)
KEGGREST 1.42.0 2023-10-26 [1] Bioconductor
KernSmooth 2.23-22 2023-07-10 [1] CRAN (R 4.3.2)
knitr 1.45 2023-10-30 [1] CRAN (R 4.3.1)
labeling 0.4.3 2023-08-29 [1] CRAN (R 4.3.0)
later 1.3.2 2023-12-06 [1] CRAN (R 4.3.1)
lattice 0.22-5 2023-10-24 [1] CRAN (R 4.3.1)
lazyeval 0.2.2 2019-03-15 [1] CRAN (R 4.3.0)
leiden 0.4.3.1 2023-11-17 [1] CRAN (R 4.3.1)
lifecycle 1.0.4 2023-11-07 [1] CRAN (R 4.3.1)
limma 3.58.1 2023-11-02 [1] Bioconductor
listenv 0.9.1 2024-01-29 [1] CRAN (R 4.3.1)
lmtest 0.9-40 2022-03-21 [1] CRAN (R 4.3.0)
locfit 1.5-9.8 2023-06-11 [1] CRAN (R 4.3.0)
loo 2.7.0 2024-02-24 [1] CRAN (R 4.3.1)
lubridate * 1.9.3 2023-09-27 [1] CRAN (R 4.3.1)
lungref.SeuratData 2.0.0 2024-02-29 [1] local
M3Drop 1.28.0 2023-10-26 [1] Bioconductor
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)
MASS 7.3-60.0.1 2024-01-13 [1] CRAN (R 4.3.1)
Matrix * 1.6-5 2024-01-11 [1] CRAN (R 4.3.1)
MatrixGenerics * 1.14.0 2023-10-26 [1] Bioconductor
matrixStats * 1.2.0 2023-12-11 [1] CRAN (R 4.3.1)
MCMCprecision 0.4.0 2019-12-05 [1] CRAN (R 4.3.0)
memoise 2.0.1 2021-11-26 [1] CRAN (R 4.3.0)
metapod 1.10.1 2023-12-23 [1] Bioconductor 3.18 (R 4.3.2)
mgcv 1.9-1 2023-12-21 [1] CRAN (R 4.3.1)
mime 0.12 2021-09-28 [1] CRAN (R 4.3.0)
miniUI 0.1.1.1 2018-05-18 [1] CRAN (R 4.3.0)
msigdbr * 7.5.1 2022-03-30 [1] CRAN (R 4.3.0)
munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)
mvtnorm 1.2-4 2023-11-27 [1] CRAN (R 4.3.1)
nlme 3.1-164 2023-11-27 [1] CRAN (R 4.3.1)
nnet 7.3-19 2023-05-03 [1] CRAN (R 4.3.2)
numDeriv 2016.8-1.1 2019-06-06 [1] CRAN (R 4.3.0)
openssl 2.1.1 2023-09-25 [1] CRAN (R 4.3.1)
org.Hs.eg.db * 3.18.0 2024-02-27 [1] Bioconductor
OrganismDbi * 1.44.0 2023-10-26 [1] Bioconductor
parallelly 1.37.0 2024-02-14 [1] CRAN (R 4.3.1)
patchwork * 1.2.0 2024-01-08 [1] CRAN (R 4.3.1)
pbapply 1.7-2 2023-06-27 [1] CRAN (R 4.3.0)
pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)
pkgbuild 1.4.3 2023-12-10 [1] CRAN (R 4.3.1)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)
plotly 4.10.4 2024-01-13 [1] CRAN (R 4.3.1)
plyr 1.8.9 2023-10-02 [1] CRAN (R 4.3.1)
png 0.1-8 2022-11-29 [1] CRAN (R 4.3.0)
polyclip 1.10-6 2023-09-27 [1] CRAN (R 4.3.1)
poweRlaw 0.80.0 2024-01-25 [1] CRAN (R 4.3.1)
pracma 2.4.4 2023-11-10 [1] CRAN (R 4.3.1)
presto 1.0.0 2024-02-27 [1] Github (immunogenomics/presto@31dc97f)
prettyunits 1.2.0 2023-09-24 [1] CRAN (R 4.3.1)
progress 1.2.3 2023-12-06 [1] CRAN (R 4.3.1)
progressr 0.14.0 2023-08-10 [1] CRAN (R 4.3.0)
promises 1.2.1 2023-08-10 [1] CRAN (R 4.3.0)
ProtGenerics 1.34.0 2023-10-26 [1] Bioconductor
proxyC 0.3.4 2023-10-25 [1] CRAN (R 4.3.1)
purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)
QuickJSR 1.1.3 2024-01-31 [1] CRAN (R 4.3.1)
R.methodsS3 1.8.2 2022-06-13 [1] CRAN (R 4.3.0)
R.oo 1.26.0 2024-01-24 [1] CRAN (R 4.3.1)
R.utils 2.12.3 2023-11-18 [1] CRAN (R 4.3.1)
R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)
RANN 2.6.1 2019-01-08 [1] CRAN (R 4.3.0)
rappdirs 0.3.3 2021-01-31 [1] CRAN (R 4.3.0)
RBGL 1.78.0 2023-10-26 [1] Bioconductor
RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.3.0)
Rcpp 1.0.12 2024-01-09 [1] CRAN (R 4.3.1)
RcppAnnoy 0.0.22 2024-01-23 [1] CRAN (R 4.3.1)
RcppEigen 0.3.3.9.4 2023-11-02 [1] CRAN (R 4.3.1)
RcppHNSW 0.6.0 2024-02-04 [1] CRAN (R 4.3.1)
RcppParallel 5.1.7 2023-02-27 [1] CRAN (R 4.3.0)
RcppRoll 0.3.0 2018-06-05 [1] CRAN (R 4.3.0)
RCurl 1.98-1.14 2024-01-09 [1] CRAN (R 4.3.1)
readr * 2.1.5 2024-01-10 [1] CRAN (R 4.3.1)
readxl 1.4.3 2023-07-06 [1] CRAN (R 4.3.0)
reldist 1.7-2 2023-02-17 [1] CRAN (R 4.3.0)
reshape2 1.4.4 2020-04-09 [1] CRAN (R 4.3.0)
ResidualMatrix 1.12.0 2023-11-06 [1] Bioconductor
restfulr 0.0.15 2022-06-16 [1] CRAN (R 4.3.0)
reticulate 1.35.0 2024-01-31 [1] CRAN (R 4.3.1)
rhdf5 2.46.1 2023-12-02 [1] Bioconductor 3.18 (R 4.3.2)
rhdf5filters 1.14.1 2023-12-16 [1] Bioconductor 3.18 (R 4.3.2)
Rhdf5lib 1.24.2 2024-02-10 [1] Bioconductor 3.18 (R 4.3.2)
rjson 0.2.21 2022-01-09 [1] CRAN (R 4.3.0)
rlang 1.1.3 2024-01-10 [1] CRAN (R 4.3.1)
rmarkdown 2.25 2023-09-18 [1] CRAN (R 4.3.1)
robustbase 0.99-2 2024-01-27 [1] CRAN (R 4.3.1)
ROCR 1.0-11 2020-05-02 [1] CRAN (R 4.3.0)
rpart 4.1.23 2023-12-05 [1] CRAN (R 4.3.1)
rprojroot 2.0.4 2023-11-05 [1] CRAN (R 4.3.1)
Rsamtools 2.18.0 2023-10-26 [1] Bioconductor
RSpectra 0.16-1 2022-04-24 [1] CRAN (R 4.3.0)
RSQLite 2.3.5 2024-01-21 [1] CRAN (R 4.3.1)
rstan 2.32.5 2024-01-10 [1] CRAN (R 4.3.1)
rstantools 2.4.0 2024-01-31 [1] CRAN (R 4.3.1)
rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)
rsvd 1.0.5 2021-04-16 [1] CRAN (R 4.3.0)
rtracklayer 1.62.0 2023-10-26 [1] Bioconductor
Rtsne 0.17 2023-12-07 [1] CRAN (R 4.3.1)
ruv 0.9.7.1 2019-08-30 [1] CRAN (R 4.3.0)
S4Arrays 1.2.0 2023-10-26 [1] Bioconductor
S4Vectors * 0.40.2 2023-11-25 [1] Bioconductor 3.18 (R 4.3.2)
sass 0.4.8 2023-12-06 [1] CRAN (R 4.3.1)
ScaledMatrix 1.10.0 2023-11-06 [1] Bioconductor
scales * 1.3.0 2023-11-28 [1] CRAN (R 4.3.1)
scater * 1.30.1 2023-11-16 [1] Bioconductor
scattermore 1.2 2023-06-12 [1] CRAN (R 4.3.0)
scDblFinder * 1.16.0 2023-12-23 [1] Bioconductor 3.18 (R 4.3.2)
scMerge * 1.18.0 2023-12-30 [1] Bioconductor 3.18 (R 4.3.2)
scran * 1.30.2 2024-01-23 [1] Bioconductor 3.18 (R 4.3.2)
sctransform 0.4.1 2023-10-19 [1] CRAN (R 4.3.1)
scuttle * 1.12.0 2023-11-06 [1] Bioconductor
seqLogo 1.68.0 2023-10-26 [1] Bioconductor
sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)
Seurat * 5.0.1.9009 2024-02-28 [1] Github (satijalab/seurat@6a3ef5e)
SeuratData 0.2.2.9001 2024-02-28 [1] Github (satijalab/seurat-data@0cce240)
SeuratDisk 0.0.0.9021 2024-02-27 [1] Github (mojaveazure/seurat-disk@877d4e1)
SeuratObject * 5.0.1 2023-11-17 [1] CRAN (R 4.3.1)
sfsmisc 1.1-17 2024-02-01 [1] CRAN (R 4.3.1)
shiny 1.8.0 2023-11-17 [1] CRAN (R 4.3.1)
shinyBS * 0.61.1 2022-04-17 [1] CRAN (R 4.3.0)
shinydashboard 0.7.2 2021-09-30 [1] CRAN (R 4.3.0)
shinyjs 2.1.0 2021-12-23 [1] CRAN (R 4.3.0)
Signac 1.12.0 2023-11-08 [1] CRAN (R 4.3.1)
SingleCellExperiment * 1.24.0 2023-11-06 [1] Bioconductor
snakecase 0.11.1 2023-08-27 [1] CRAN (R 4.3.0)
sp * 2.1-3 2024-01-30 [1] CRAN (R 4.3.1)
spam 2.10-0 2023-10-23 [1] CRAN (R 4.3.1)
SparseArray 1.2.4 2024-02-10 [1] Bioconductor 3.18 (R 4.3.2)
sparseMatrixStats 1.14.0 2023-10-26 [1] Bioconductor
spatstat.data 3.0-4 2024-01-15 [1] CRAN (R 4.3.1)
spatstat.explore 3.2-6 2024-02-01 [1] CRAN (R 4.3.1)
spatstat.geom 3.2-8 2024-01-26 [1] CRAN (R 4.3.1)
spatstat.random 3.2-2 2023-11-29 [1] CRAN (R 4.3.1)
spatstat.sparse 3.0-3 2023-10-24 [1] CRAN (R 4.3.1)
spatstat.utils 3.0-4 2023-10-24 [1] CRAN (R 4.3.1)
StanHeaders 2.32.5 2024-01-10 [1] CRAN (R 4.3.1)
startupmsg 0.9.6.1 2024-02-12 [1] CRAN (R 4.3.1)
statmod 1.5.0 2023-01-06 [1] CRAN (R 4.3.0)
stringi 1.8.3 2023-12-11 [1] CRAN (R 4.3.1)
stringr * 1.5.1 2023-11-14 [1] CRAN (R 4.3.1)
SummarizedExperiment * 1.32.0 2023-11-06 [1] Bioconductor
survival 3.5-8 2024-02-14 [1] CRAN (R 4.3.1)
tensor 1.5 2012-05-05 [1] CRAN (R 4.3.0)
TFBSTools 1.40.0 2023-10-24 [1] Bioconductor
TFMPvalue 0.0.9 2022-10-21 [1] CRAN (R 4.3.0)
tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)
tidyr * 1.3.1 2024-01-24 [1] CRAN (R 4.3.1)
tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)
tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)
timechange 0.3.0 2024-01-18 [1] CRAN (R 4.3.1)
tonsilref.SeuratData 2.0.0 2024-02-29 [1] local
TxDb.Hsapiens.UCSC.hg19.knownGene * 3.2.2 2024-02-27 [1] Bioconductor
tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)
utf8 1.2.4 2023-10-22 [1] CRAN (R 4.3.1)
uwot 0.1.16 2023-06-29 [1] CRAN (R 4.3.0)
vctrs 0.6.5 2023-12-01 [1] CRAN (R 4.3.1)
vipor 0.4.7 2023-12-18 [1] CRAN (R 4.3.1)
viridis 0.6.5 2024-01-29 [1] CRAN (R 4.3.1)
viridisLite 0.4.2 2023-05-02 [1] CRAN (R 4.3.0)
whisker 0.4.1 2022-12-05 [1] CRAN (R 4.3.0)
withr 3.0.0 2024-01-16 [1] CRAN (R 4.3.1)
workflowr 1.7.1 2023-08-23 [1] CRAN (R 4.3.0)
WriteXLS 6.5.0 2024-01-09 [1] CRAN (R 4.3.1)
xfun 0.42 2024-02-08 [1] CRAN (R 4.3.1)
xgboost 1.7.7.1 2024-01-25 [1] CRAN (R 4.3.1)
XML 3.99-0.16.1 2024-01-22 [1] CRAN (R 4.3.1)
xml2 1.3.6 2023-12-04 [1] CRAN (R 4.3.1)
xtable 1.8-4 2019-04-21 [1] CRAN (R 4.3.0)
XVector 0.42.0 2023-10-26 [1] Bioconductor
yaml 2.3.8 2023-12-11 [1] CRAN (R 4.3.1)
zlibbioc 1.48.0 2023-10-26 [1] Bioconductor
zoo 1.8-12 2023-04-13 [1] CRAN (R 4.3.0)
[1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library
──────────────────────────────────────────────────────────────────────────────
sessionInfo()R version 4.3.2 (2023-10-31)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Australia/Melbourne
tzcode source: internal
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] ggstats_0.5.1
[2] googlesheets4_1.1.1
[3] scMerge_1.18.0
[4] scDblFinder_1.16.0
[5] Azimuth_0.5.0
[6] shinyBS_0.61.1
[7] decontX_1.0.0
[8] celda_1.18.1
[9] Matrix_1.6-5
[10] Seurat_5.0.1.9009
[11] SeuratObject_5.0.1
[12] sp_2.1-3
[13] EnsDb.Hsapiens.v86_2.99.0
[14] ensembldb_2.26.0
[15] AnnotationFilter_1.26.0
[16] msigdbr_7.5.1
[17] Homo.sapiens_1.3.1
[18] TxDb.Hsapiens.UCSC.hg19.knownGene_3.2.2
[19] org.Hs.eg.db_3.18.0
[20] GO.db_3.18.0
[21] OrganismDbi_1.44.0
[22] GenomicFeatures_1.54.3
[23] AnnotationDbi_1.64.1
[24] scales_1.3.0
[25] patchwork_1.2.0
[26] cowplot_1.1.3
[27] janitor_2.2.0
[28] scater_1.30.1
[29] scran_1.30.2
[30] scuttle_1.12.0
[31] SingleCellExperiment_1.24.0
[32] SummarizedExperiment_1.32.0
[33] Biobase_2.62.0
[34] GenomicRanges_1.54.1
[35] GenomeInfoDb_1.38.6
[36] IRanges_2.36.0
[37] S4Vectors_0.40.2
[38] BiocGenerics_0.48.1
[39] MatrixGenerics_1.14.0
[40] matrixStats_1.2.0
[41] glue_1.7.0
[42] here_1.0.1
[43] lubridate_1.9.3
[44] forcats_1.0.0
[45] stringr_1.5.1
[46] dplyr_1.1.4
[47] purrr_1.0.2
[48] readr_2.1.5
[49] tidyr_1.3.1
[50] tibble_3.2.1
[51] ggplot2_3.5.0
[52] tidyverse_2.0.0
[53] BiocParallel_1.36.0
[54] BiocStyle_2.30.0
loaded via a namespace (and not attached):
[1] igraph_2.0.2 graph_1.80.0
[3] Formula_1.2-5 ica_1.0-3
[5] plotly_4.10.4 zlibbioc_1.48.0
[7] tidyselect_1.2.0 bit_4.0.5
[9] doParallel_1.0.17 lattice_0.22-5
[11] rjson_0.2.21 M3Drop_1.28.0
[13] blob_1.2.4 S4Arrays_1.2.0
[15] parallel_4.3.2 seqLogo_1.68.0
[17] png_0.1-8 ResidualMatrix_1.12.0
[19] cli_3.6.2 askpass_1.2.0
[21] ProtGenerics_1.34.0 openssl_2.1.1
[23] goftest_1.2-3 gargle_1.5.2
[25] BiocIO_1.12.0 bluster_1.12.0
[27] densEstBayes_1.0-2.2 BiocNeighbors_1.20.2
[29] Signac_1.12.0 uwot_0.1.16
[31] curl_5.2.0 mime_0.12
[33] evaluate_0.23 leiden_0.4.3.1
[35] stringi_1.8.3 backports_1.4.1
[37] XML_3.99-0.16.1 httpuv_1.6.14
[39] magrittr_2.0.3 rappdirs_0.3.3
[41] splines_4.3.2 RcppRoll_0.3.0
[43] DT_0.32 sctransform_0.4.1
[45] ggbeeswarm_0.7.2 sessioninfo_1.2.2
[47] DBI_1.2.2 jquerylib_0.1.4
[49] withr_3.0.0 git2r_0.33.0
[51] rprojroot_2.0.4 xgboost_1.7.7.1
[53] lmtest_0.9-40 RBGL_1.78.0
[55] bdsmatrix_1.3-6 rtracklayer_1.62.0
[57] BiocManager_1.30.22 htmlwidgets_1.6.4
[59] fs_1.6.3 biomaRt_2.58.2
[61] ggrepel_0.9.5 labeling_0.4.3
[63] SparseArray_1.2.4 DEoptimR_1.1-3
[65] cellranger_1.1.0 annotate_1.80.0
[67] reticulate_1.35.0 zoo_1.8-12
[69] JASPAR2020_0.99.10 XVector_0.42.0
[71] knitr_1.45 TFBSTools_1.40.0
[73] TFMPvalue_0.0.9 timechange_0.3.0
[75] foreach_1.5.2 fansi_1.0.6
[77] caTools_1.18.2 grid_4.3.2
[79] data.table_1.15.0 rhdf5_2.46.1
[81] ruv_0.9.7.1 R.oo_1.26.0
[83] poweRlaw_0.80.0 RSpectra_0.16-1
[85] irlba_2.3.5.1 fastDummies_1.7.3
[87] ellipsis_0.3.2 lazyeval_0.2.2
[89] yaml_2.3.8 survival_3.5-8
[91] scattermore_1.2 crayon_1.5.2
[93] RcppAnnoy_0.0.22 RColorBrewer_1.1-3
[95] progressr_0.14.0 later_1.3.2
[97] base64enc_0.1-3 ggridges_0.5.6
[99] codetools_0.2-19 KEGGREST_1.42.0
[101] bbmle_1.0.25.1 Rtsne_0.17
[103] startupmsg_0.9.6.1 limma_3.58.1
[105] Rsamtools_2.18.0 filelock_1.0.3
[107] foreign_0.8-86 pkgconfig_2.0.3
[109] xml2_1.3.6 sfsmisc_1.1-17
[111] GenomicAlignments_1.38.2 spatstat.sparse_3.0-3
[113] BSgenome_1.70.2 viridisLite_0.4.2
[115] xtable_1.8-4 highr_0.10
[117] plyr_1.8.9 httr_1.4.7
[119] tools_4.3.2 globals_0.16.2
[121] pkgbuild_1.4.3 checkmate_2.3.1
[123] htmlTable_2.4.2 beeswarm_0.4.0
[125] nlme_3.1-164 loo_2.7.0
[127] dbplyr_2.4.0 hdf5r_1.3.9
[129] shinyjs_2.1.0 digest_0.6.34
[131] numDeriv_2016.8-1.1 farver_2.1.1
[133] tzdb_0.4.0 reshape2_1.4.4
[135] cvTools_0.3.2 WriteXLS_6.5.0
[137] viridis_0.6.5 rpart_4.1.23
[139] DirichletMultinomial_1.44.0 cachem_1.0.8
[141] BiocFileCache_2.10.1 polyclip_1.10-6
[143] proxyC_0.3.4 Hmisc_5.1-1
[145] generics_0.1.3 Biostrings_2.70.2
[147] mvtnorm_1.2-4 googledrive_2.1.1
[149] presto_1.0.0 parallelly_1.37.0
[151] statmod_1.5.0 RcppHNSW_0.6.0
[153] ScaledMatrix_1.10.0 pbapply_1.7-2
[155] spam_2.10-0 dqrng_0.3.2
[157] utf8_1.2.4 StanHeaders_2.32.5
[159] gtools_3.9.5 readxl_1.4.3
[161] RcppEigen_0.3.3.9.4 gridExtra_2.3
[163] shiny_1.8.0 GenomeInfoDbData_1.2.11
[165] R.utils_2.12.3 rhdf5filters_1.14.1
[167] RCurl_1.98-1.14 memoise_2.0.1
[169] rmarkdown_2.25 R.methodsS3_1.8.2
[171] future_1.33.1 RANN_2.6.1
[173] spatstat.data_3.0-4 rstudioapi_0.15.0
[175] cluster_2.1.6 QuickJSR_1.1.3
[177] whisker_0.4.1 rstantools_2.4.0
[179] spatstat.utils_3.0-4 hms_1.1.3
[181] fitdistrplus_1.1-11 munsell_0.5.0
[183] colorspace_2.1-0 rlang_1.1.3
[185] DelayedMatrixStats_1.24.0 sparseMatrixStats_1.14.0
[187] dotCall64_1.1-1 shinydashboard_0.7.2
[189] dbscan_1.1-12 mgcv_1.9-1
[191] xfun_0.42 CNEr_1.38.0
[193] iterators_1.0.14 reldist_1.7-2
[195] abind_1.4-5 MCMCprecision_0.4.0
[197] rstan_2.32.5 Rhdf5lib_1.24.2
[199] bitops_1.0-7 promises_1.2.1
[201] inline_0.3.19 RSQLite_2.3.5
[203] DelayedArray_0.28.0 compiler_4.3.2
[205] prettyunits_1.2.0 beachmat_2.18.1
[207] listenv_0.9.1 BSgenome.Hsapiens.UCSC.hg38_1.4.5
[209] Rcpp_1.0.12 tonsilref.SeuratData_2.0.0
[211] enrichR_3.2 edgeR_4.0.16
[213] workflowr_1.7.1 BiocSingular_1.18.0
[215] tensor_1.5 MASS_7.3-60.0.1
[217] progress_1.2.3 babelgene_22.9
[219] spatstat.random_3.2-2 R6_2.5.1
[221] fastmap_1.1.1 fastmatch_1.1-4
[223] distr_2.9.3 vipor_0.4.7
[225] ROCR_1.0-11 SeuratDisk_0.0.0.9021
[227] nnet_7.3-19 rsvd_1.0.5
[229] gtable_0.3.4 KernSmooth_2.23-22
[231] lungref.SeuratData_2.0.0 miniUI_0.1.1.1
[233] deldir_2.0-2 htmltools_0.5.7
[235] RcppParallel_5.1.7 bit64_4.0.5
[237] spatstat.explore_3.2-6 lifecycle_1.0.4
[239] restfulr_0.0.15 sass_0.4.8
[241] vctrs_0.6.5 robustbase_0.99-2
[243] spatstat.geom_3.2-8 snakecase_0.11.1
[245] SeuratData_0.2.2.9001 future.apply_1.11.1
[247] pracma_2.4.4 batchelor_1.18.1
[249] bslib_0.6.1 pillar_1.9.0
[251] gplots_3.1.3.1 metapod_1.10.1
[253] locfit_1.5-9.8 combinat_0.0-8
[255] jsonlite_1.8.8