Subclustering: Nasal_brushings
Unsupervised Clustering of Broad cell labels
Gunjan Dixit
September 26, 2024
Last updated: 2024-09-26
Checks: 6 1
Knit directory: paed-airway-allTissues/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of
the R Markdown file created these results, you’ll want to first commit
it to the Git repo. If you’re still working on the analysis, you can
ignore this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230811) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 952acbb. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.DS_Store
Ignored: data/.DS_Store
Ignored: data/RDS/
Ignored: output/.DS_Store
Ignored: output/CSV/.DS_Store
Ignored: output/G000231_Neeland_batch1/
Ignored: output/G000231_Neeland_batch2_1/
Ignored: output/G000231_Neeland_batch2_2/
Ignored: output/G000231_Neeland_batch3/
Ignored: output/G000231_Neeland_batch4/
Ignored: output/G000231_Neeland_batch5/
Ignored: output/G000231_Neeland_batch9_1/
Ignored: output/RDS/
Ignored: output/plots/
Untracked files:
Untracked: Adenoids_Bcell_subset_proportions_Age.pdf
Untracked: Adenoids_Tcell_subset_proportions_Age.pdf
Untracked: Adenoids_cell_type_proportions_Age.pdf
Untracked: Age_proportions_Adenoids.pdf
Untracked: Age_proportions_Bronchial_brushings.pdf
Untracked: Age_proportions_Nasal_brushings.pdf
Untracked: Age_proportions_Tonsils.pdf
Untracked: BAL_Tcell_propeller.xlsx
Untracked: BAL_propeller.xlsx
Untracked: BB_Tcell_propeller.xlsx
Untracked: BB_propeller.xlsx
Untracked: NB_Tcell_propeller.xlsx
Untracked: NB_propeller.csv
Untracked: NB_propeller.pdf
Untracked: NB_propeller.xlsx
Untracked: Tonsils_cell_type_proportions.jpg
Untracked: Tonsils_cell_type_proportions.pdf
Untracked: Tonsils_cell_type_proportions.png
Untracked: Tonsils_cell_type_proportions_Age.pdf
Untracked: analysis/03_Batch_Integration.Rmd
Untracked: analysis/Age_modelling_Adenoids.Rmd
Untracked: analysis/Age_modelling_Bronchial_Brushings.Rmd
Untracked: analysis/Age_modelling_Nasal_Brushings.Rmd
Untracked: analysis/Age_modelling_Tonsils.Rmd
Untracked: analysis/Age_proportions.Rmd
Untracked: analysis/Age_proportions_AllBatches.Rmd
Untracked: analysis/BAL_without_DecontX.Rmd
Untracked: analysis/Batch_Integration_&_Downstream_analysis.Rmd
Untracked: analysis/Batch_correction_&_Downstream.Rmd
Untracked: analysis/Boxplot_Adenoids.pdf
Untracked: analysis/Boxplot_BAL.pdf
Untracked: analysis/Boxplot_Bronchial_brushings.pdf
Untracked: analysis/Boxplot_Nasal_brushings.pdf
Untracked: analysis/Boxplot_Tonsils.pdf
Untracked: analysis/Cell_cycle_regression.Rmd
Untracked: analysis/Master_metadata.Rmd
Untracked: analysis/Preprocessing_Batch1_Nasal_brushings.Rmd
Untracked: analysis/Preprocessing_Batch2_Tonsils.Rmd
Untracked: analysis/Preprocessing_Batch3_Adenoids.Rmd
Untracked: analysis/Preprocessing_Batch4_Bronchial_brushings.Rmd
Untracked: analysis/Preprocessing_Batch5_Nasal_brushings.Rmd
Untracked: analysis/Preprocessing_Batch6_BAL.Rmd
Untracked: analysis/Preprocessing_Batch7_Bronchial_brushings.Rmd
Untracked: analysis/Preprocessing_Batch8_Adenoids.Rmd
Untracked: analysis/Preprocessing_Batch9_Tonsils.Rmd
Untracked: analysis/TonsilsVsAdenoids.Rmd
Untracked: analysis/boxplot_proportions_Adenoids.pdf
Untracked: analysis/boxplot_proportions_BAL.pdf
Untracked: analysis/boxplot_proportions_Bronchial_brushings.pdf
Untracked: analysis/boxplot_proportions_Nasal_brushings.pdf
Untracked: analysis/boxplot_proportions_Tonsils.pdf
Untracked: analysis/boxplot_proportions__broad_l2Adenoids.pdf
Untracked: analysis/boxplot_proportions__broad_l2BAL.pdf
Untracked: analysis/boxplot_proportions__broad_l2Bronchial_brushings.pdf
Untracked: analysis/boxplot_proportions__broad_l2Nasal_brushings.pdf
Untracked: analysis/boxplot_proportions__broad_l2Tonsils.pdf
Untracked: analysis/cell_cycle_regression.R
Untracked: analysis/test.Rmd
Untracked: analysis/testing_age_all.Rmd
Untracked: cell_proportions_overview.png
Untracked: cell_type_proportions.pdf
Untracked: cell_type_proportions_enhanced.pdf
Untracked: cell_type_proportions_individual.pdf
Untracked: color_palette.rds
Untracked: color_palette_v2_level2.rds
Untracked: combined_metadata.rds
Untracked: data/Cell_labels_Mel/
Untracked: data/Cell_labels_Mel_v2/
Untracked: data/Cell_labels_modified_Gunjan/
Untracked: data/Hs.c2.cp.reactome.v7.1.entrez.rds
Untracked: data/Raw_feature_bc_matrix/
Untracked: data/celltypes_Mel_GD_v3.xlsx
Untracked: data/celltypes_Mel_GD_v4_no_dups.xlsx
Untracked: data/celltypes_Mel_modified.xlsx
Untracked: data/celltypes_Mel_v2.csv
Untracked: data/celltypes_Mel_v2.xlsx
Untracked: data/celltypes_Mel_v2_MN.xlsx
Untracked: data/celltypes_for_mel_MN.xlsx
Untracked: data/earlyAIR_sample_sheets_combined.xlsx
Untracked: output/CSV/All_tissues.propeller.xlsx
Untracked: output/CSV/Bronchial_brushings/
Untracked: output/CSV/Bronchial_brushings_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/
Untracked: output/CSV/G000231_Neeland_Adenoids.propeller.xlsx
Untracked: output/CSV/G000231_Neeland_Bronchial_brushings.propeller.xlsx
Untracked: output/CSV/G000231_Neeland_Nasal_brushings.propeller.xlsx
Untracked: output/CSV/G000231_Neeland_Tonsils.propeller.xlsx
Untracked: output/CSV/Nasal_brushings/
Unstaged changes:
Deleted: 02_QC_exploratoryPlots.Rmd
Deleted: 02_QC_exploratoryPlots.html
Modified: analysis/00_AllBatches_overview.Rmd
Modified: analysis/01_QC_emptyDrops.Rmd
Modified: analysis/02_QC_exploratoryPlots.Rmd
Modified: analysis/Adenoids.Rmd
Modified: analysis/Age_modeling.Rmd
Modified: analysis/AllBatches_QCExploratory.Rmd
Modified: analysis/BAL.Rmd
Modified: analysis/Bronchial_brushings.Rmd
Modified: analysis/Nasal_brushings.Rmd
Modified: analysis/Subclustering_Nasal_brushings.Rmd
Modified: analysis/Tonsils.Rmd
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c0.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c1.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c10.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c11.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c12.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c13.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c14.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c15.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c16.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c17.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c2.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c3.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c4.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c5.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c6.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c7.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c8.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/REACTOME-cluster-limma-c9.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c0.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c1.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c10.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c11.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c12.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c13.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c14.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c15.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c16.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c17.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c2.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c3.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c4.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c5.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c6.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c7.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c8.csv
Modified: output/CSV/BAL_Marker_gene_clusters.limmaTrendRNA_snn_res.0.4/up-cluster-limma-c9.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_0.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_1.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_10.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_11.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_2.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_3.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_4.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_5.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_6.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_7.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_8.csv
Deleted: output/CSV/Nasal_brushings_Marker_genes_Reclustered_Bcell_population.RNA_snn_res.0.2/G000231_Neeland_Nasal_brushings_cluster_9.csv
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown
(analysis/Subclustering_Nasal_brushings.Rmd) and HTML
(docs/Subclustering_Nasal_brushings.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 952acbb | Gunjan Dixit | 2024-09-26 | Added B cell subclustering html |
| Rmd | 77b017d | Gunjan Dixit | 2024-09-26 | Added B cell subclustering |
| html | 07af966 | Gunjan Dixit | 2024-09-25 | Modified index |
| Rmd | 3b5ab22 | Gunjan Dixit | 2024-09-25 | Separated Subclustering Rmd |
Introduction
Load libraries
suppressPackageStartupMessages({
library(BiocStyle)
library(tidyverse)
library(here)
library(glue)
library(dplyr)
library(Seurat)
library(clustree)
library(kableExtra)
library(RColorBrewer)
library(data.table)
library(ggplot2)
library(patchwork)
library(limma)
library(edgeR)
library(speckle)
library(AnnotationDbi)
library(org.Hs.eg.db)
library(readxl)
})Load Input data
Load merged object (batch corrected/integrated) for the tissue.
tissue <- "Nasal_brushings"
out1 <- here("output",
"RDS", "AllBatches_Clustering_SEUs",
paste0("G000231_Neeland_",tissue,".Clusters.SEU.rds"))
merged_obj <- readRDS(out1)
merged_objAn object of class Seurat
17973 features across 74812 samples within 1 assay
Active assay: RNA (17973 features, 2000 variable features)
3 layers present: data, counts, scale.data
4 dimensional reductions calculated: pca, umap.unintegrated, harmony, umap.harmonyReclustering T cell population
This includes CD4 T cell, CD8 T cell, NK cell, NK-T cell, proliferating or cycling T/NK cell.
The marker genes for this reclustering can be found here-
idx <- which(Idents(merged_obj) %in% c("CD4 T cells", "CD8 T cells", "NK-T cells", "proliferating T/NK"))
paed_sub <- merged_obj[,idx]
mito_genes <- grep("^MT-", rownames(paed_sub), value = TRUE)
paed_sub <- subset(paed_sub, features = setdiff(rownames(paed_sub), mito_genes))
paed_subAn object of class Seurat
17962 features across 21491 samples within 1 assay
Active assay: RNA (17962 features, 2000 variable features)
3 layers present: data, counts, scale.data
4 dimensional reductions calculated: pca, umap.unintegrated, harmony, umap.harmonypaed_sub <- paed_sub %>%
NormalizeData() %>%
FindVariableFeatures() %>%
ScaleData() %>%
RunPCA()
paed_sub <- RunUMAP(paed_sub, dims = 1:30, reduction = "pca", reduction.name = "umap.new")
meta_data_columns <- colnames(paed_sub@meta.data)
columns_to_remove <- grep("^RNA_snn_res", meta_data_columns, value = TRUE)
paed_sub@meta.data <- paed_sub@meta.data[, !(colnames(paed_sub@meta.data) %in% columns_to_remove)]
resolutions <- seq(0.1, 1, by = 0.1)
paed_sub <- FindNeighbors(paed_sub, reduction = "pca", dims = 1:30)
paed_sub <- FindClusters(paed_sub, resolution = resolutions, algorithm = 3)Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.9444
Number of communities: 6
Elapsed time: 15 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.9168
Number of communities: 8
Elapsed time: 13 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.9021
Number of communities: 11
Elapsed time: 12 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8894
Number of communities: 13
Elapsed time: 11 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8772
Number of communities: 14
Elapsed time: 11 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8676
Number of communities: 17
Elapsed time: 11 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8589
Number of communities: 17
Elapsed time: 10 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8509
Number of communities: 19
Elapsed time: 10 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8430
Number of communities: 20
Elapsed time: 10 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 21491
Number of edges: 703338
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8360
Number of communities: 21
Elapsed time: 10 secondsDimHeatmap(paed_sub, dims = 1:10, cells = 500, balanced = TRUE)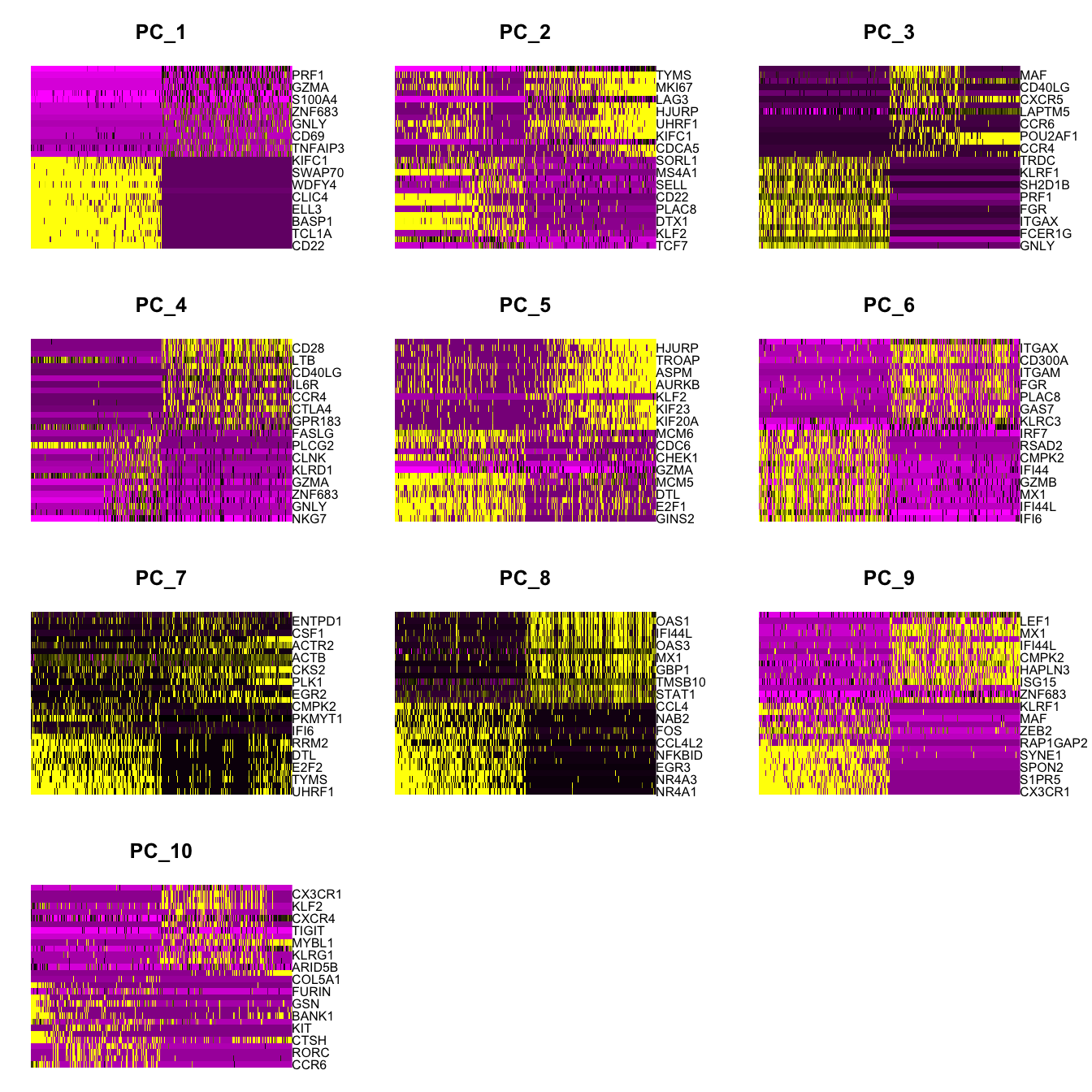
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
clustree(paed_sub, prefix = "RNA_snn_res.")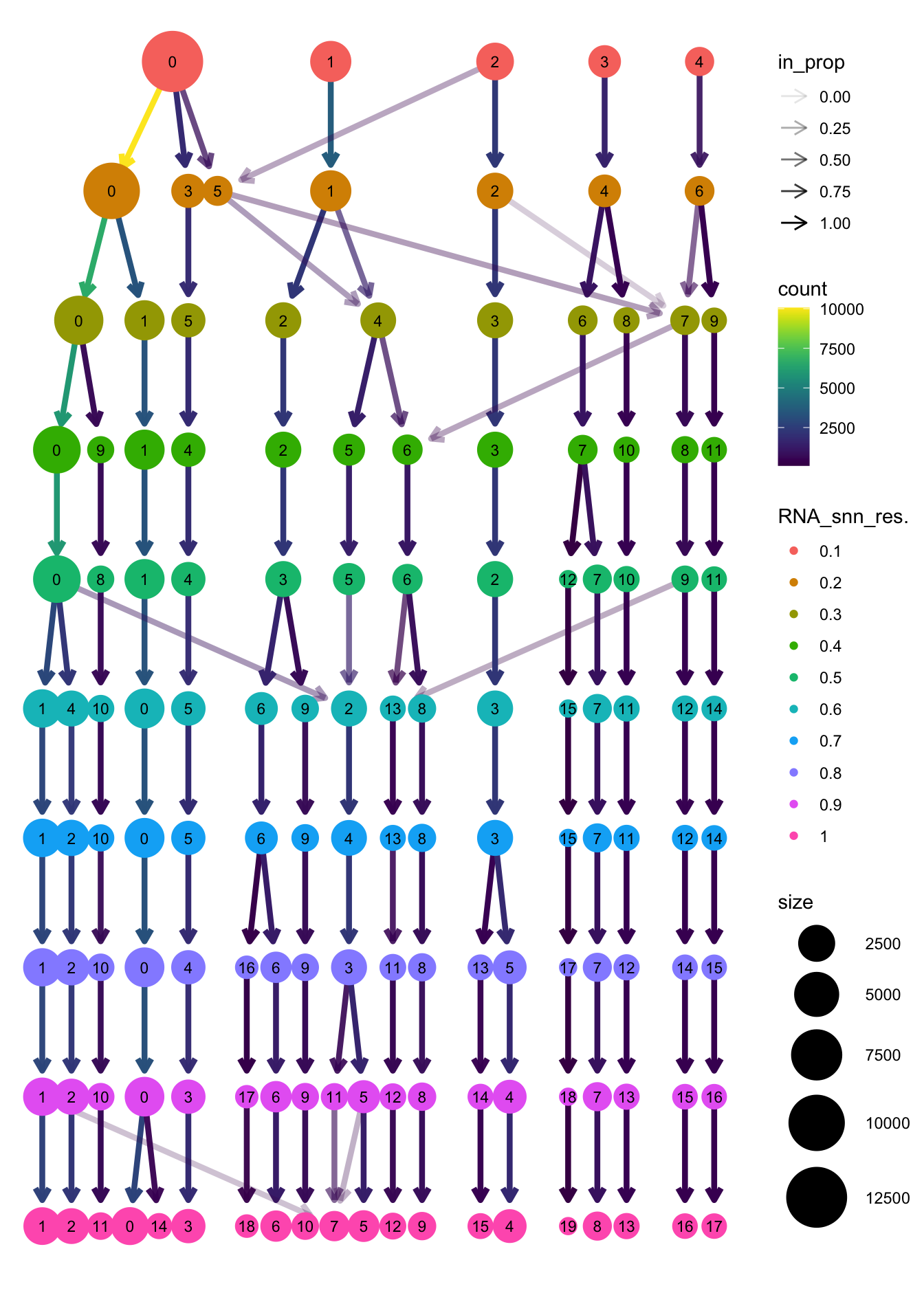
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
opt_res <- "RNA_snn_res.0.4"
n <- nlevels(paed_sub$RNA_snn_res.0.4)
paed_sub$RNA_snn_res.0.4 <- factor(paed_sub$RNA_snn_res.0.4, levels = seq(0,n-1))
paed_sub$seurat_clusters <- NULL
Idents(paed_sub) <- paed_sub$RNA_snn_res.0.4DimPlot(paed_sub, reduction = "umap.new", group.by = "RNA_snn_res.0.4", label = TRUE, label.size = 4.5, repel = TRUE, raster = FALSE )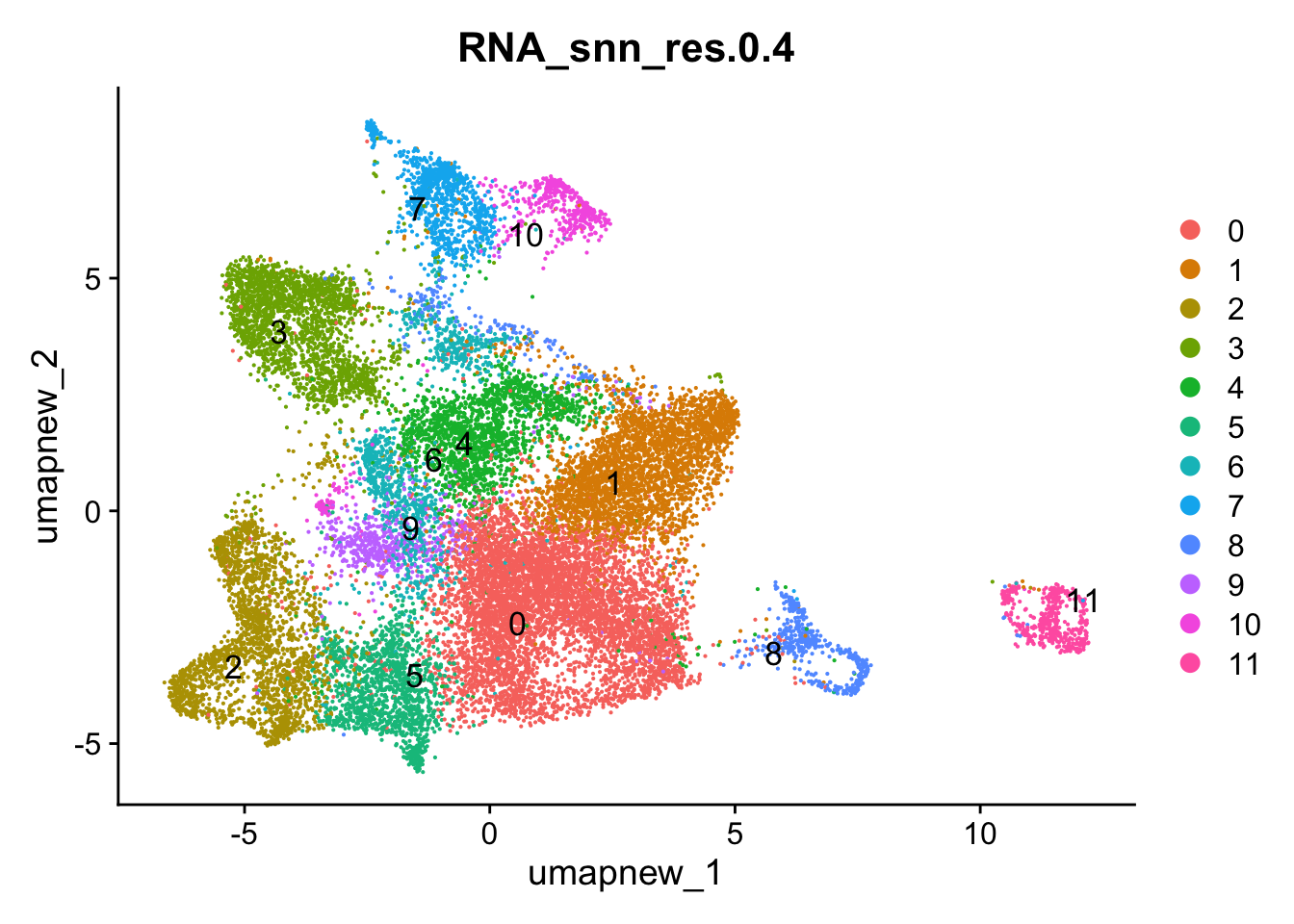
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
paed_sub.markers <- FindAllMarkers(paed_sub, only.pos = TRUE, min.pct = 0.25, logfc.threshold = 0.25)Calculating cluster 0Calculating cluster 1Calculating cluster 2Calculating cluster 3Calculating cluster 4Calculating cluster 5Calculating cluster 6Calculating cluster 7Calculating cluster 8Calculating cluster 9Calculating cluster 10Calculating cluster 11paed_sub.markers %>%
group_by(cluster) %>% unique() %>%
top_n(n = 5, wt = avg_log2FC) -> top5
paed_sub.markers %>%
group_by(cluster) %>%
slice_head(n=1) %>%
pull(gene) -> best.wilcox.gene.per.cluster
best.wilcox.gene.per.cluster [1] "CD8A" "CSF1" "CD4" "TCF7" "IFI6" "MAF" "NR4A2" "ITGAX" "TYMS"
[10] "GZMK" "KLF2" "CD79A"FeaturePlot(paed_sub,features=best.wilcox.gene.per.cluster, reduction = 'umap.new', raster = FALSE, label = T, ncol = 3)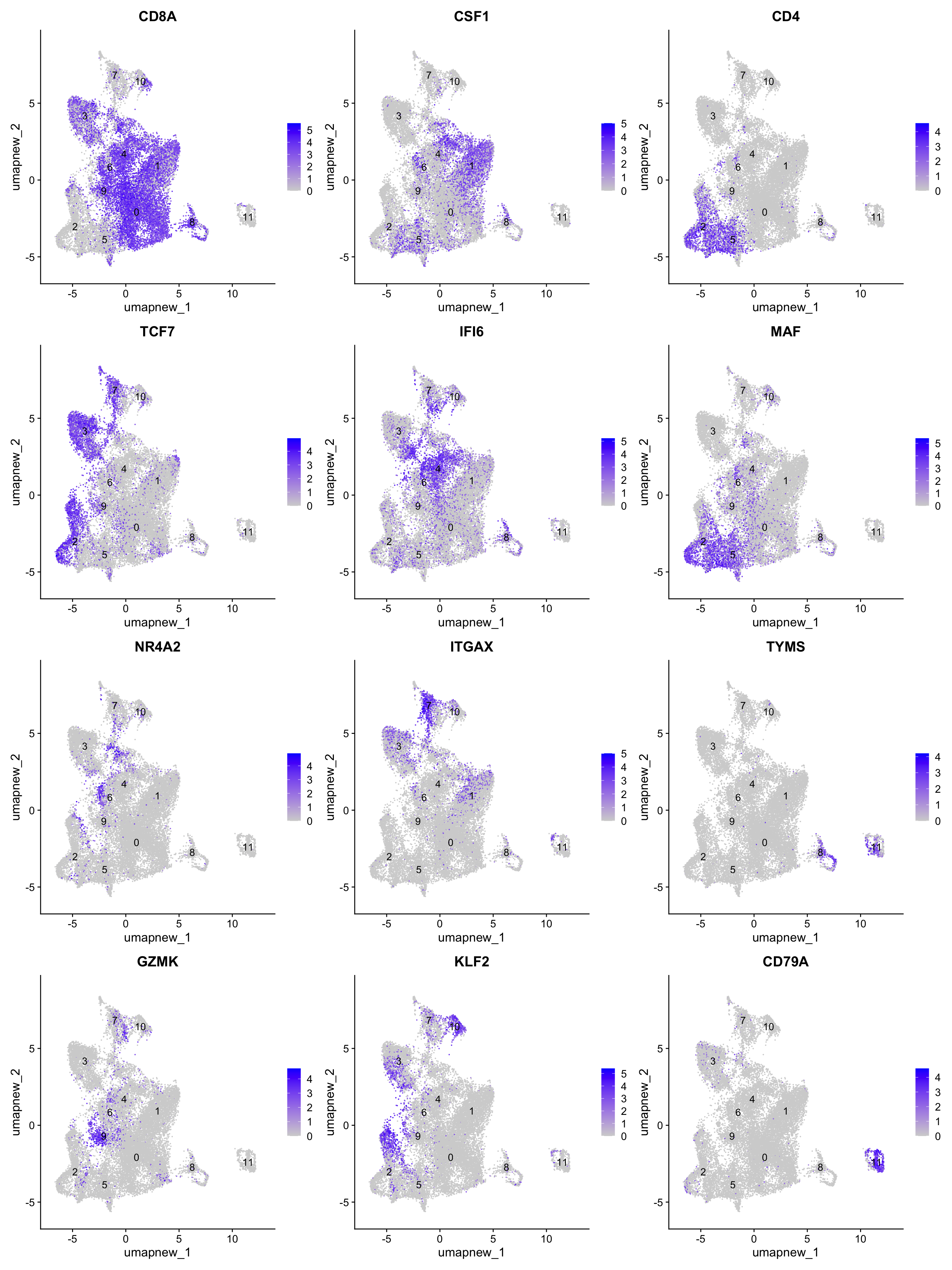
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
Top 10 marker genes from Seurat
## Seurat top markers
top10 <- paed_sub.markers %>%
group_by(cluster) %>%
top_n(n = 10, wt = avg_log2FC) %>%
ungroup() %>%
distinct(gene, .keep_all = TRUE) %>%
arrange(cluster, desc(avg_log2FC))
cluster_colors <- paletteer::paletteer_d("pals::glasbey")[factor(top10$cluster)]
DotPlot(paed_sub,
features = unique(top10$gene),
group.by = opt_res,
cols = c("azure1", "blueviolet"),
dot.scale = 3, assay = "RNA") +
RotatedAxis() +
FontSize(y.text = 8, x.text = 12) +
labs(y = element_blank(), x = element_blank()) +
coord_flip() +
theme(axis.text.y = element_text(color = cluster_colors)) +
ggtitle("Top 10 marker genes per cluster (Seurat)")Warning: Vectorized input to `element_text()` is not officially supported.
ℹ Results may be unexpected or may change in future versions of ggplot2.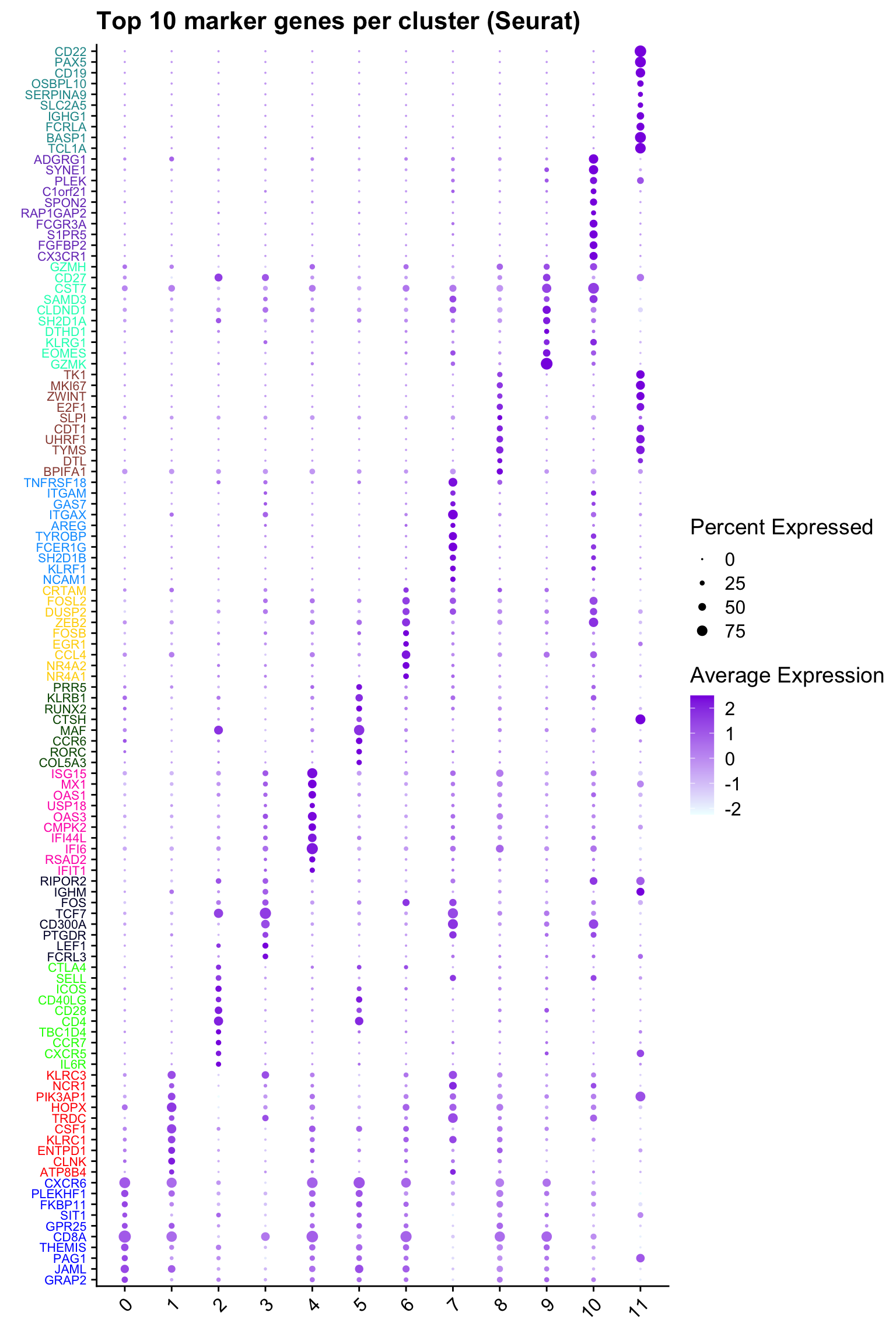
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
out_markers <- here("output",
"CSV",
paste(tissue,"_Marker_genes_Reclustered_Tcell_population.",opt_res, sep = ""))
dir.create(out_markers, recursive = TRUE, showWarnings = FALSE)
for (cl in unique(paed_sub.markers$cluster)) {
cluster_data <- paed_sub.markers %>% dplyr::filter(cluster == cl)
file_name <- here(out_markers, paste0("G000231_Neeland_",tissue, "_cluster_", cl, ".csv"))
if (!file.exists(file_name)) {
write.csv(cluster_data, file = file_name)
}
}Update T cell subclustering labels
cell_labels <- readxl::read_excel(here("data/Cell_labels_Mel_v2/earlyAIR_NB_BB_BAL_T-NK_annotations_16.07.24.xlsx"), sheet = "NB")
new_cluster_names <- cell_labels %>%
dplyr::select(cluster, annotation) %>%
deframe()
paed_sub <- RenameIdents(paed_sub, new_cluster_names)
paed_sub@meta.data$cell_labels_v2 <- Idents(paed_sub)
DimPlot(paed_sub, reduction = "umap.new", raster = FALSE, repel = TRUE, label = TRUE, label.size = 3.5) + ggtitle(paste0(tissue, ": UMAP with Updated subclustering"))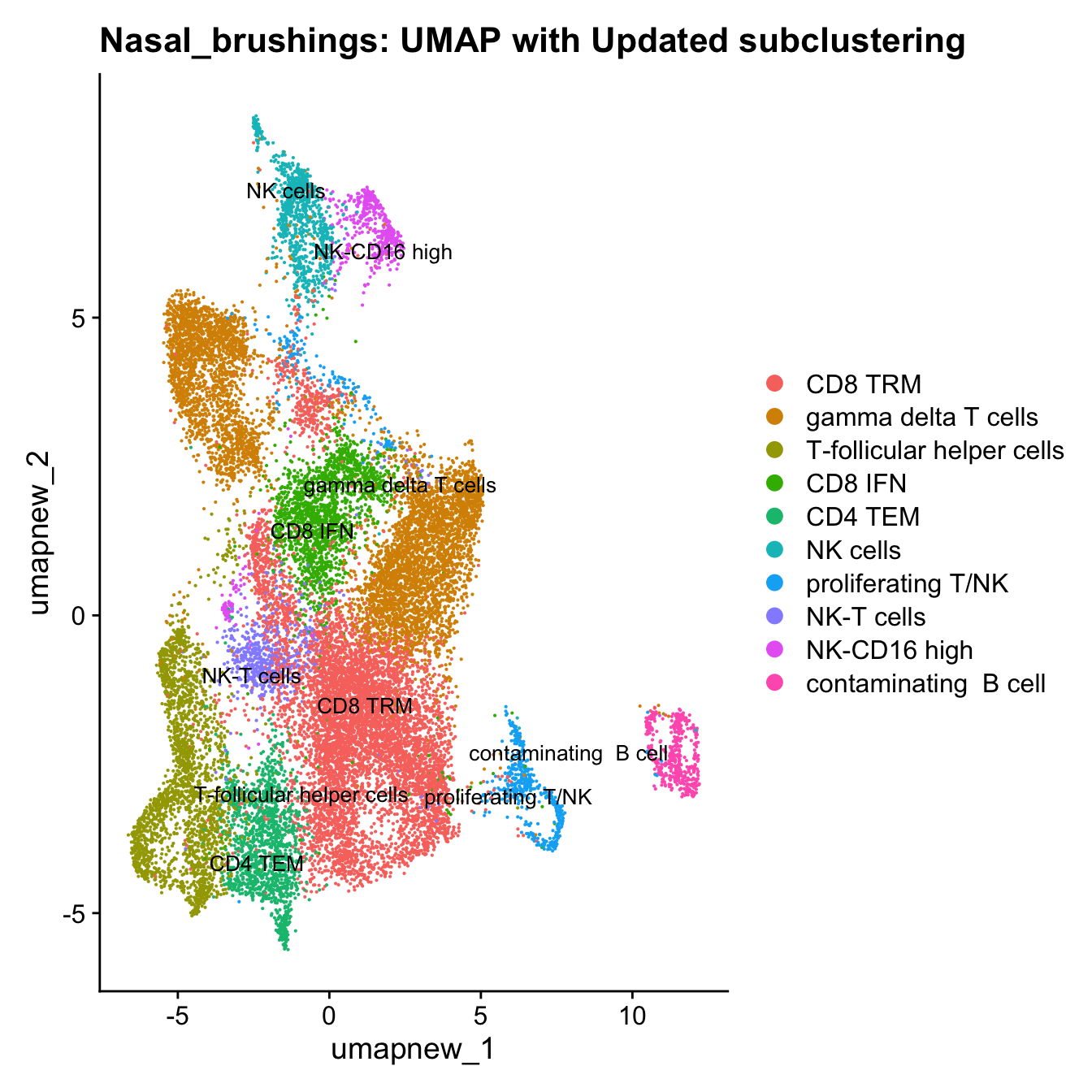
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
paed_sub@meta.data %>%
ggplot(aes(x = cell_labels_v2, fill = cell_labels_v2)) +
geom_bar() +
geom_text(aes(label = ..count..), stat = "count",
vjust = -0.5, colour = "black", size = 2) +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
NoLegend() + ggtitle(paste0(tissue, " : Counts per cell-type"))Warning: The dot-dot notation (`..count..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(count)` instead.
This warning is displayed once every 8 hours.
Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
generated.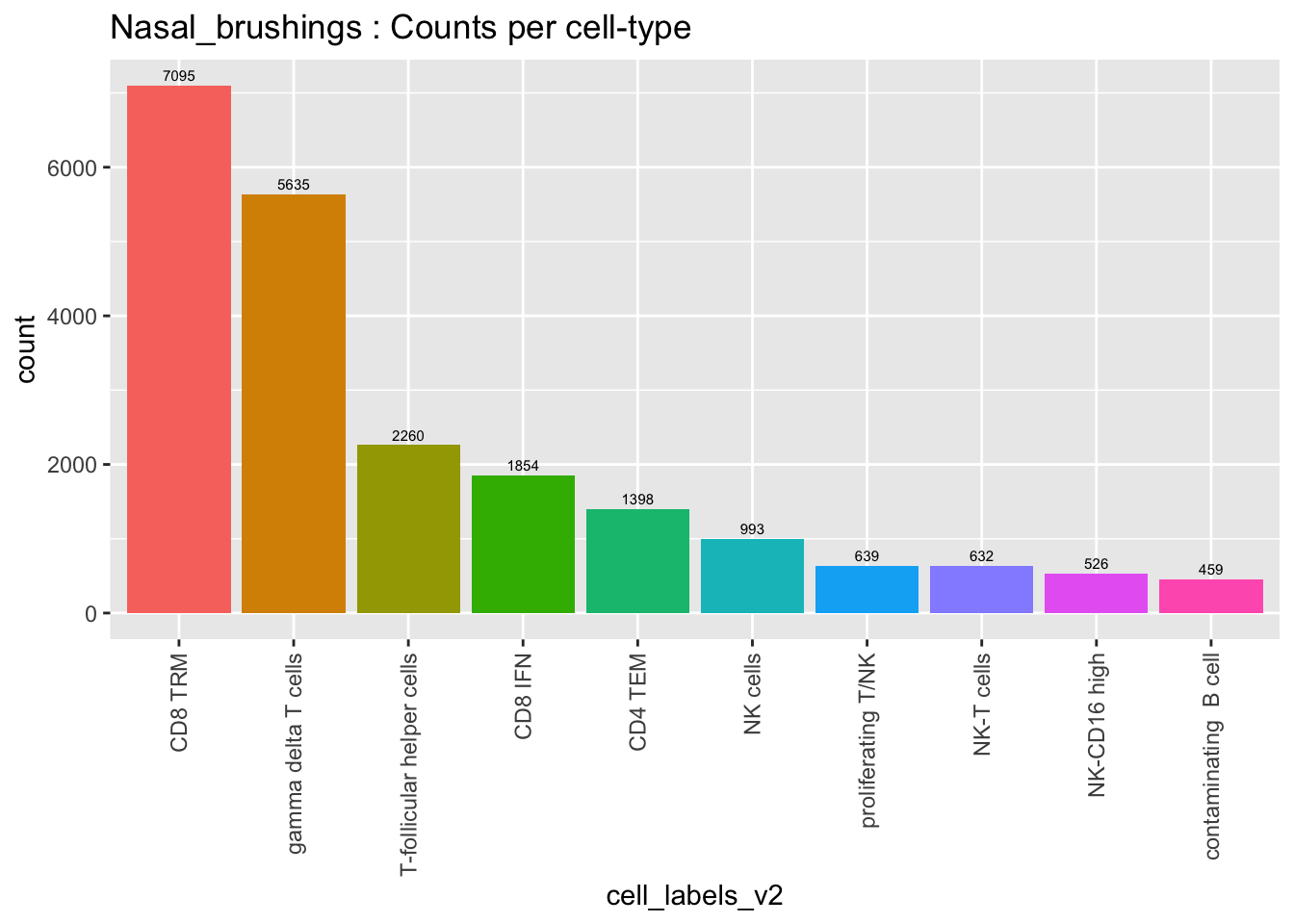
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
Additional QC plots for Proliferatink T/NK cluster
FeaturePlot(merged_obj, features=c("CD19", "MKI67"), reduction = 'umap.harmony', raster = FALSE, label = T, ncol = 2)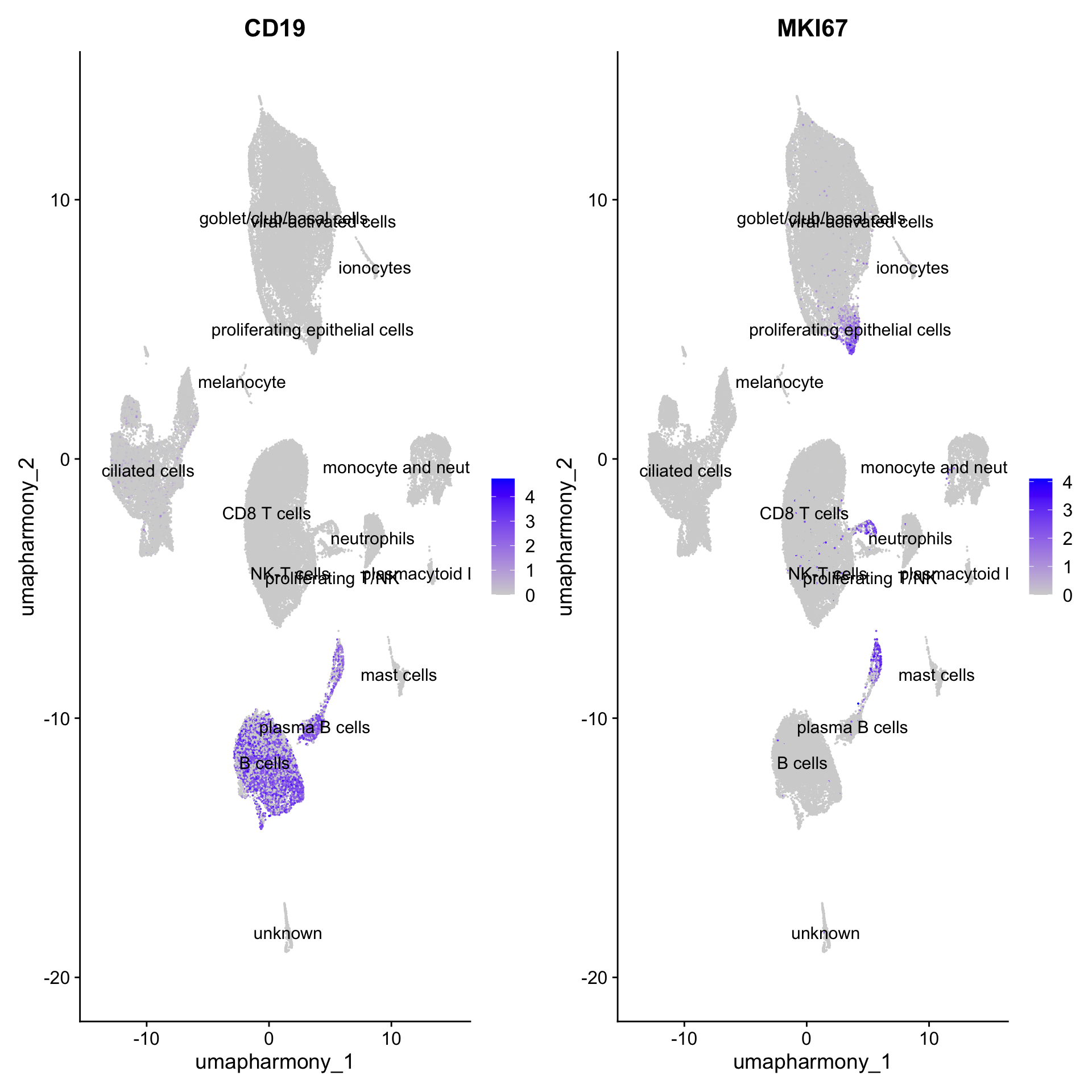
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
DimPlot(merged_obj, reduction = "umap.harmony", group.by = "predicted.ann_level_4", label = TRUE)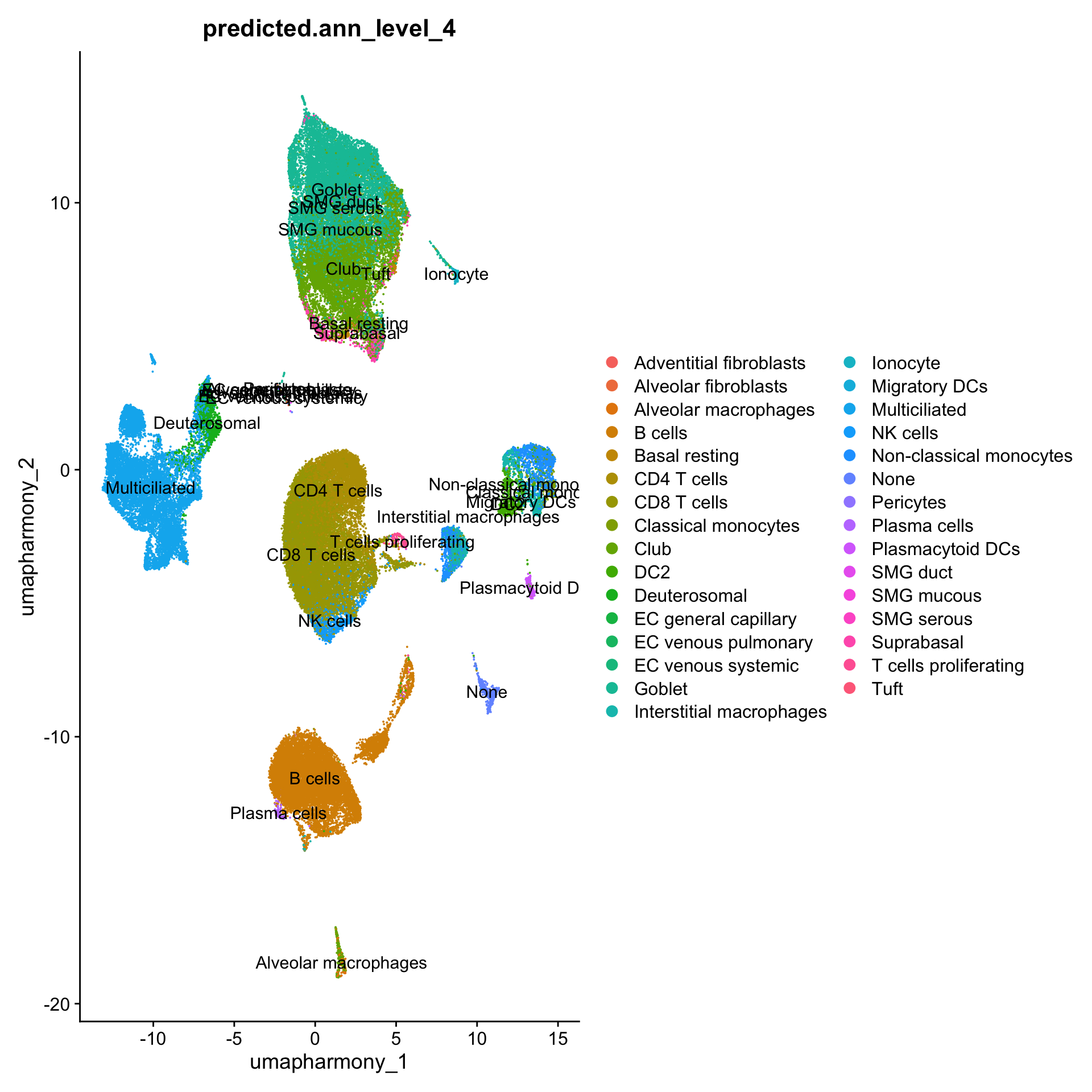
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
cl_16 <- as.data.frame(table(merged_obj$predicted.ann_level_4[merged_obj$RNA_snn_res.0.4 == "16"]))
colnames(cl_16) <- c("CellType", "Count")
cl_16 <- cl_16 %>% filter(Count > 0)
ggplot(cl_16, aes(x = reorder(CellType, Count), y = Count, fill = CellType)) +
geom_bar(stat = "identity") +
geom_text(aes(label = Count), hjust = -0.3) +
coord_flip() +
labs(title = "Azimuth (level4) cell types in Cluster 16 or Proliferating T/NK cells", x = "Cell Type", y = "Count") +
theme_minimal() +
theme(legend.position = "none") 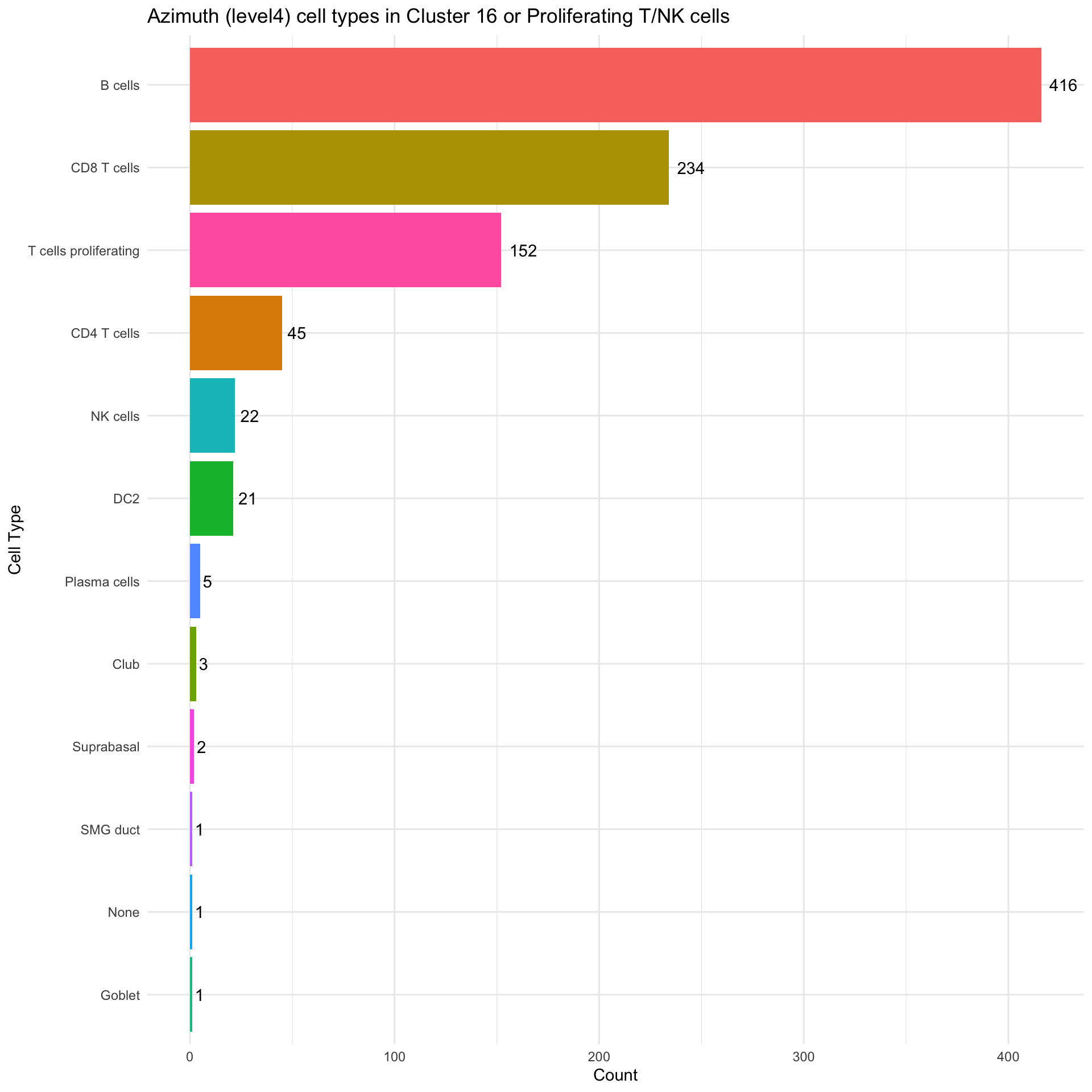
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
#FeaturePlot(merged_obj, features = c('nCount_RNA',"nFeature_RNA"), pt.size=0.2, label = T, ncol =2)
#VlnPlot(merged_obj,features = c("nCount_RNA","nFeature_RNA"), pt.size = 0) &
#theme(plot.title = element_text(size=10))
#VlnPlot(merged_obj,features = c("sum","detected"), pt.size = 0) &
#theme(plot.title = element_text(size=10))Idents(merged_obj) <- merged_obj$cluster
cl16_cells <- WhichCells(merged_obj, idents = 16)
Idents(merged_obj) <- merged_obj$predicted.ann_level_4
cl_azimuth_proliferating_Tcells <- WhichCells(merged_obj, idents = "T cells proliferating")
DimPlot(paed_sub, reduction = "umap.new", group.by = "RNA_snn_res.0.4", label = TRUE, label.size = 4.5, repel = TRUE, raster = FALSE , cells.highlight = cl16_cells)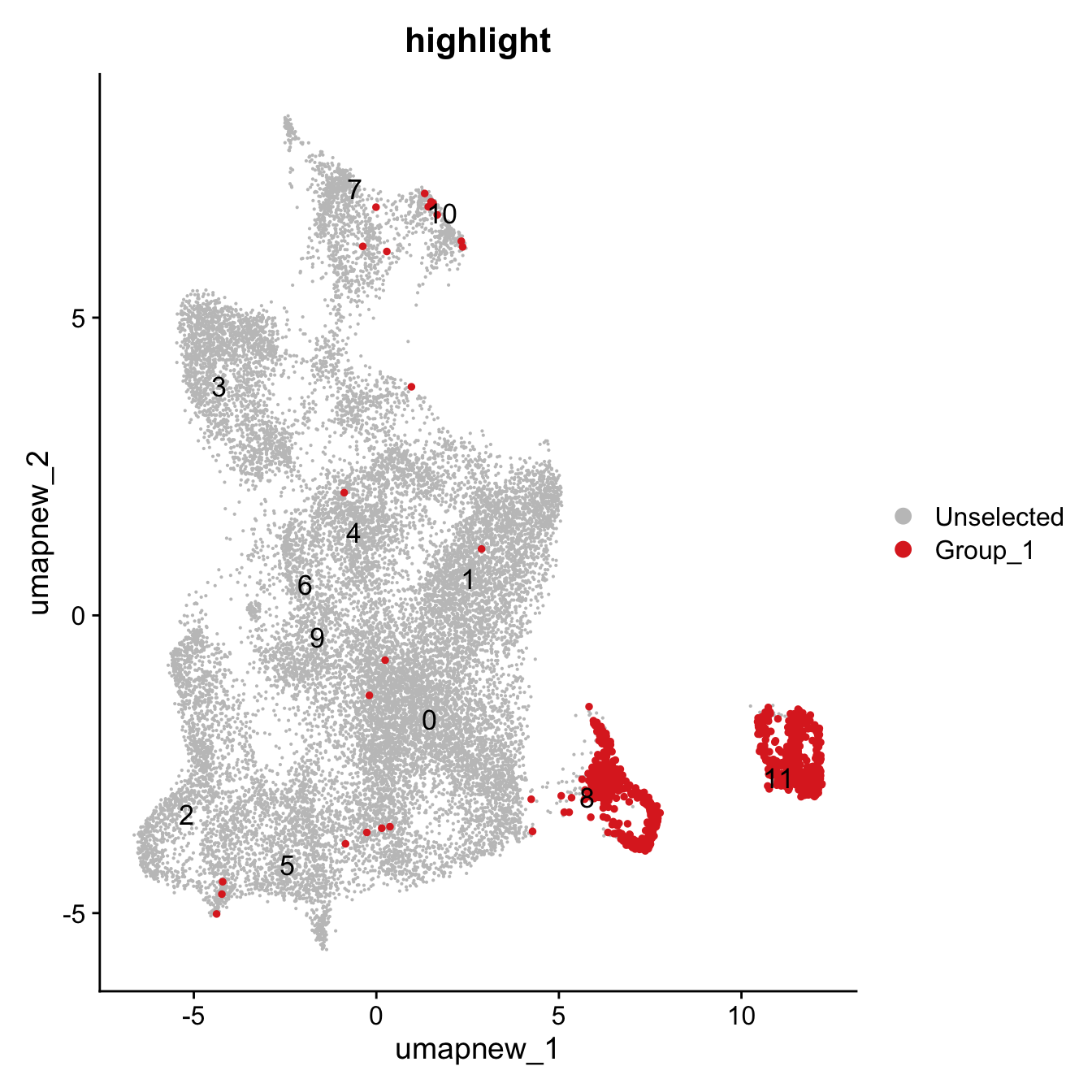
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
DimPlot(paed_sub, reduction = "umap.new", label = TRUE, label.size = 4.5, repel = TRUE, raster = FALSE , cells.highlight = cl_azimuth_proliferating_Tcells)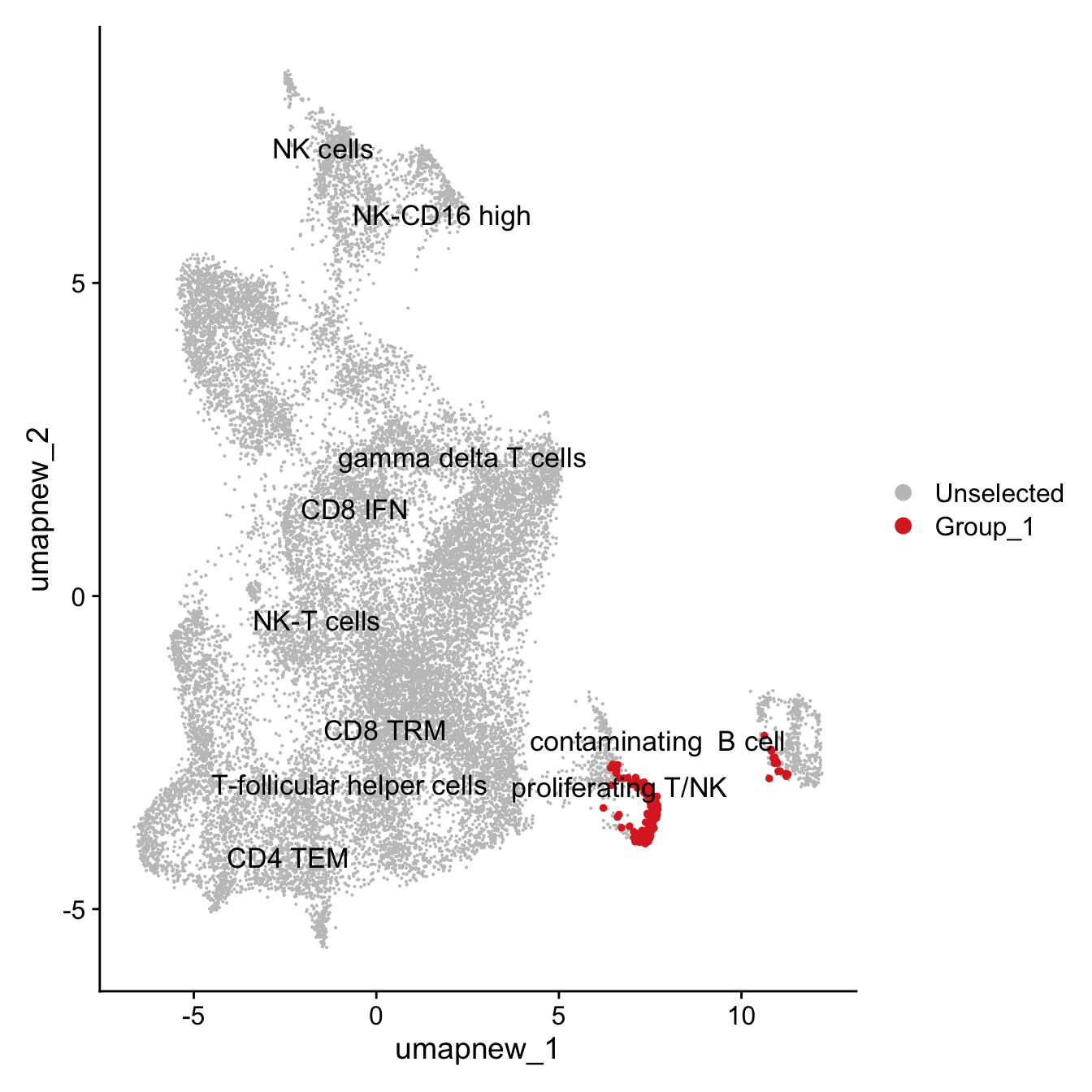
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
DimPlot(paed_sub, reduction = "umap.new", group.by = "predicted.ann_level_4", label = TRUE, label.size = 4.5, repel = TRUE, raster = FALSE)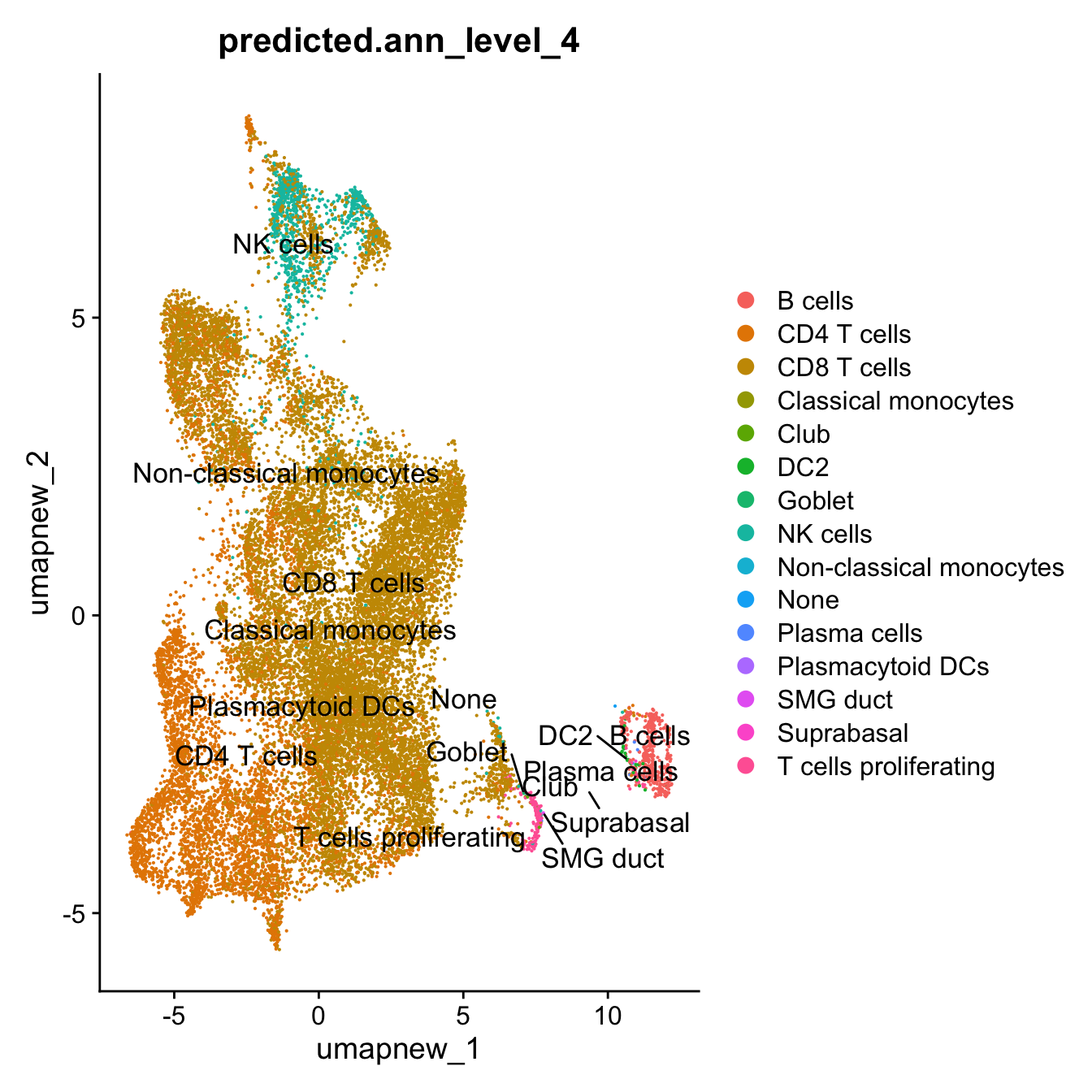
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
Save subclustered SEU object
out2 <- here("output",
"RDS", "AllBatches_Subclustering_SEUs", tissue,
paste0("G000231_Neeland_",tissue,".Tcell_population.subclusters.SEU.rds"))
#dir.create(out2)
if (!file.exists(out2)) {
saveRDS(paed_sub, file = out2)
}Excluding contaminating labels
idx <- which(grepl("^contaminating", Idents(paed_sub)))
paed_clean <- paed_sub[, -idx]paed_clean <- paed_clean %>%
NormalizeData() %>%
FindVariableFeatures() %>%
ScaleData() %>%
RunPCA()Normalizing layer: countsFinding variable features for layer countsCentering and scaling data matrixWarning: Different features in new layer data than already exists for
scale.dataPC_ 1
Positive: TYMS, UHRF1, KIFC1, MKI67, RRM2, MYBL2, HIST1H1B, STMN1, ZWINT, TOP2A
TK1, BIRC5, FOXM1, HJURP, CDT1, CDK1, AURKB, E2F2, CDCA5, HIST1H2BH
ASF1B, SPC24, ESPL1, PKMYT1, TPX2, DLGAP5, ANLN, DTL, E2F1, NCAPG
Negative: TCF7, LTB, IL7R, TXNIP, CD300A, KLF2, PLAC8, PTGDR, LEF1, TXK
TSC22D3, SATB1, FOS, FCRL3, ITGAX, MAL, DTX1, FCMR, ITGAM, SORL1
RASGRP2, CHST2, CCR7, GAS7, CNR2, RASA3, SOCS3, BACH2, DUSP2, TRDC
PC_ 2
Positive: CD300A, FCER1G, ITGAX, TYROBP, GNLY, PLAC8, SH2D1B, KLRF1, KLF2, FGR
IRF8, DUSP2, ITGAM, NCAM1, AREG, TCF7, FOSL2, TXK, GAS7, CTSW
SELL, PTGDR, FCGR3A, TNFRSF18, S1PR5, TRDC, FOS, SAMD3, NCR1, LITAF
Negative: CXCR6, CCR5, TRBC2, ALOX5AP, ITGA1, JUN, RORA, S100A4, CCR6, ST8SIA1
COL5A1, MAF, IL26, GZMA, TOX2, CD4, B3GALT2, CSF1, SCUBE1, CXCL13
LAG3, PDCD1, SLAMF1, ADAM19, RORC, CD5, CTSH, KLRB1, IL17A, NMUR1
PC_ 3
Positive: NKG7, GZMA, HOPX, PRF1, GNLY, GZMB, KLRC1, KLRD1, ITGA1, KLRC4
ZNF683, NMUR1, PIK3AP1, FASLG, KLRC3, CTSW, CSF1, CLNK, IL2RB, CXCR6
FCRL6, KIR2DL4, ENTPD1, NCR1, GZMH, ATP8B4, CCL4, SCUBE1, ALOX5AP, ADGRG1
Negative: CD4, LTB, CD28, MAF, IL7R, SPOCK2, CD40LG, TCF7, CXCR5, IL6R
ICOS, CCR7, CD5, CCR4, CD27, KLF2, GPR183, SATB1, SELL, TBC1D4
TNFRSF25, FCMR, CTLA4, CXCR4, ACTN1, LEF1, SOCS3, RASGRP2, TNFRSF4, MAL
PC_ 4
Positive: IFI6, LAG3, IFI44L, ISG15, GZMB, MX1, IFI44, OAS3, OAS1, TYMP
CMPK2, CXCR6, RSAD2, TNFAIP3, RGS1, IFIT1, XAF1, NR4A2, IRF7, PRDM1
FOSL2, ISG20, TNFRSF1B, CD69, SRGN, PRF1, ZFP36, USP18, TENT5C, SOCS1
Negative: TCF7, ITGAX, PTGDR, LEF1, CD300A, FCRL3, KLRC4, IGHM, ZNF683, ITGAM
TRDC, KLRC3, CNR2, FGR, FCRL6, TXK, GAS7, PLAC8, CXXC5, ID3
RIPOR2, MATK, SPRY2, KLRF1, MAL, SAMD3, ACTN1, TXNIP, DYSF, CHST2
PC_ 5
Positive: EGR2, EGR3, NR4A1, NR4A3, NR4A2, ZFP36L1, TNFRSF9, EGR1, NFKBID, CRTAM
NAB2, TNFRSF18, KDM6B, CCL4L2, DUSP2, TIGIT, PHLDA1, ID3, CTLA4, IL21
XCL2, SRGN, CCL4, TOX2, KRT86, SPRY2, TNFRSF4, CCL3, ATP8B4, CSF1
Negative: IFI44L, IFI6, CMPK2, OAS3, ISG15, RSAD2, OAS1, IFIT1, MX1, XAF1
IFI44, MX2, LY6E, OAS2, USP18, GBP1, IFIT2, ISG20, IRF7, IFIT3
SAMD9L, KLF2, STAT1, GIMAP4, HERC5, MT2A, TMSB10, TYMP, RASGRP2, CX3CR1 paed_clean <- RunUMAP(paed_clean, dims = 1:30, reduction = "pca", reduction.name = "umap.clean")10:24:22 UMAP embedding parameters a = 0.9922 b = 1.112Found more than one class "dist" in cache; using the first, from namespace 'spam'Also defined by 'BiocGenerics'10:24:22 Read 21032 rows and found 30 numeric columns10:24:22 Using Annoy for neighbor search, n_neighbors = 30Found more than one class "dist" in cache; using the first, from namespace 'spam'Also defined by 'BiocGenerics'10:24:22 Building Annoy index with metric = cosine, n_trees = 500% 10 20 30 40 50 60 70 80 90 100%[----|----|----|----|----|----|----|----|----|----|**************************************************|
10:24:23 Writing NN index file to temp file /var/folders/q8/kw1r78g12qn793xm7g0zvk94x2bh70/T//RtmpewC7Yy/file5ed82829d386
10:24:23 Searching Annoy index using 1 thread, search_k = 3000
10:24:26 Annoy recall = 100%
10:24:27 Commencing smooth kNN distance calibration using 1 thread with target n_neighbors = 30
10:24:28 Initializing from normalized Laplacian + noise (using RSpectra)
10:24:28 Commencing optimization for 200 epochs, with 922708 positive edges
10:24:34 Optimization finishedDimPlot(paed_clean, reduction = "umap.clean", group.by = "cell_labels_v2",raster = FALSE, repel = TRUE, label = TRUE, label.size = 4.5) + ggtitle(paste0(tissue, ": Updated subclustering (clean)"))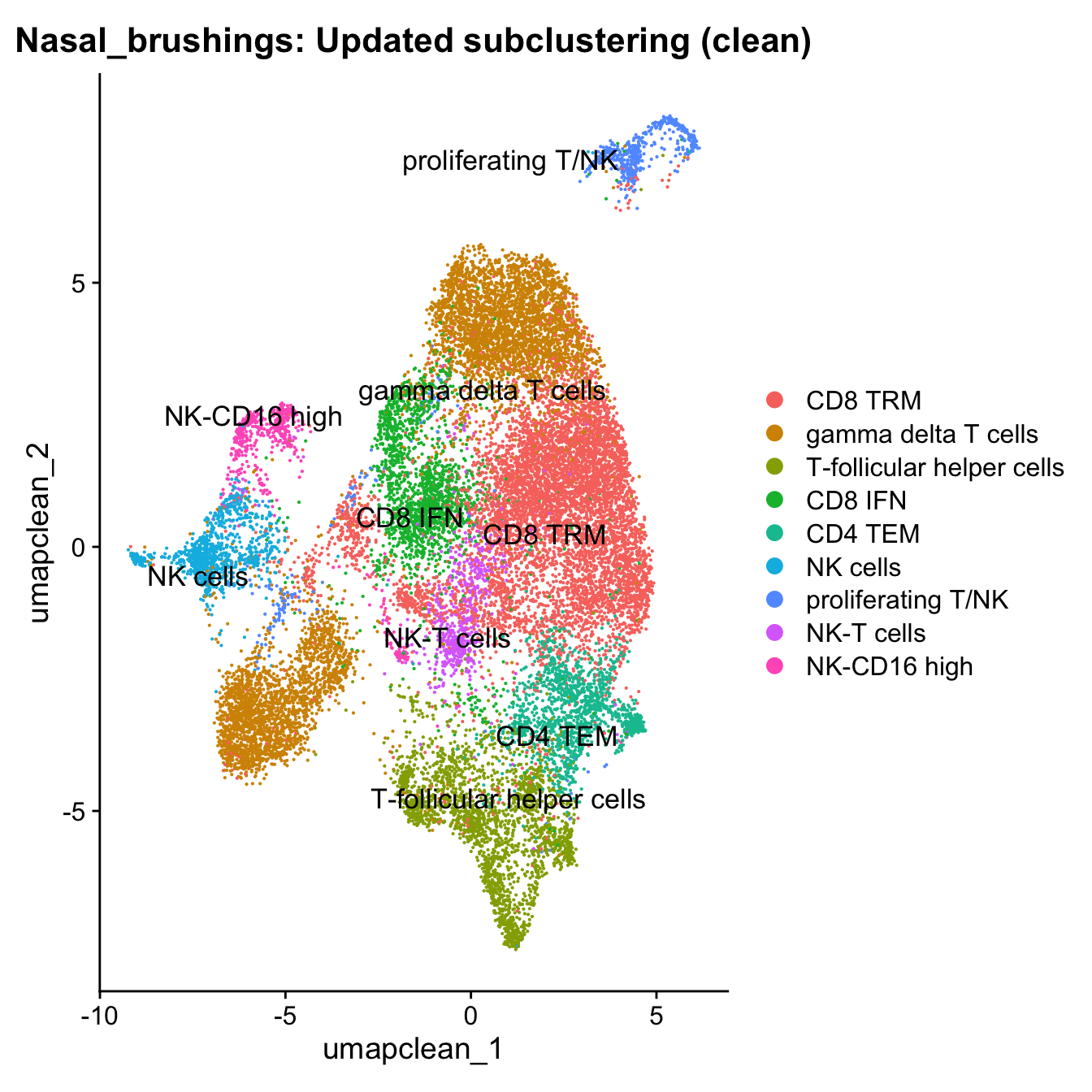
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
Summary Plots
palette1 <- paletteer::paletteer_d("ggthemes::Classic_20")
palette2 <- paletteer::paletteer_d("Polychrome::light")
combined_palette <- unique(c(palette1, palette2))
p1 <- paed_sub@meta.data %>%
dplyr::select(!!sym(opt_res), cell_labels_v2) %>% ggplot(aes(x = !!sym(opt_res),
fill = cell_labels_v2)) +
geom_bar() +
geom_text(aes(label = ..count..), stat = "count",
vjust = -0.5, colour = "black", size = 2) +
scale_y_log10() +
theme(axis.text.x = element_blank(),
axis.title.x = element_blank(),
axis.ticks.x = element_blank()) +
labs(y = "No. Cells (log scale)")
p2 <- paed_sub@meta.data %>%
dplyr::select(!!sym(opt_res), Sample) %>%
group_by(!!sym(opt_res), Sample) %>%
summarise(num = n()) %>%
mutate(prop = num / sum(num)) %>%
ggplot(aes(x = !!sym(opt_res), y = prop * 100,
fill = Sample)) +
geom_bar(stat = "identity") +
theme(axis.text.x = element_text(angle = 90,
vjust = 0.5,
hjust = 1,
size = 8)) +
labs(y = "% Cells", fill = "Sample") +
scale_fill_manual(values = combined_palette)`summarise()` has grouped output by 'RNA_snn_res.0.4'. You can override using
the `.groups` argument.# Combine the plots
(p1 / p2) & theme( legend.text = element_text(size = 8),
legend.key.size = unit(3, "mm"))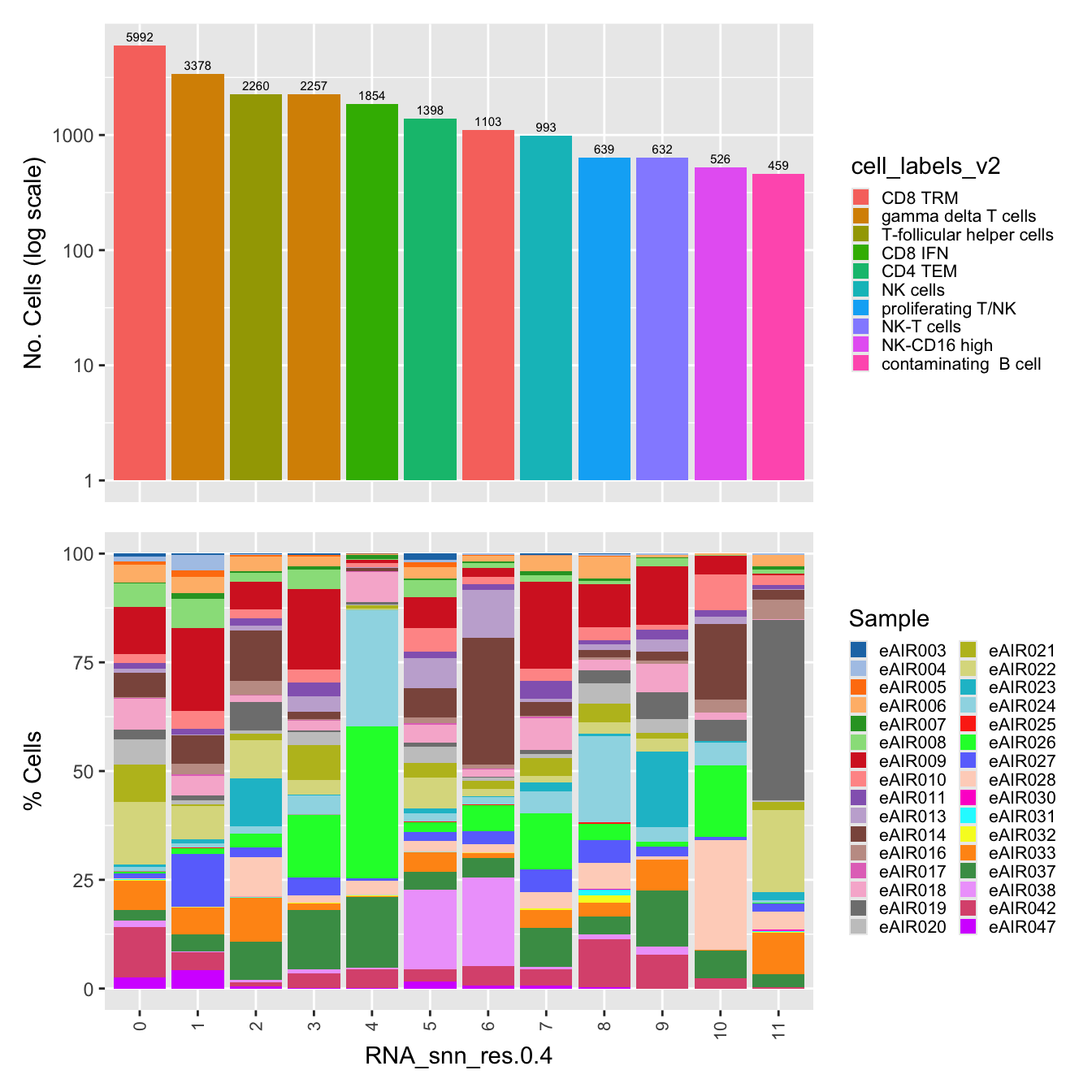
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
Other Clusters (excluding subclusters)
idx <- which(Idents(merged_obj) %in% c("CD4 T cells", "CD8 T cells", "NK-T cells", "proliferating T/NK"))
paed_other <- merged_obj[,-idx]
paed_otherAn object of class Seurat
17973 features across 54615 samples within 1 assay
Active assay: RNA (17973 features, 2000 variable features)
3 layers present: data, counts, scale.data
4 dimensional reductions calculated: pca, umap.unintegrated, harmony, umap.harmonylevels(paed_other$cell_labels)[levels(paed_other$cell_labels) == "goblet/club/basal cells"] <- "non-ciliated cells"
levels(Idents(paed_other))[levels(Idents(paed_other)) == "goblet/club/basal cells"] <- "non-ciliated cells"
paed_other$cell_labels_v2 <- Idents(paed_other)# Visualize the clustering results
DimPlot(paed_other, reduction = "umap.harmony", group.by = "cluster", label = TRUE, label.size = 2.5, repel = TRUE, raster = FALSE )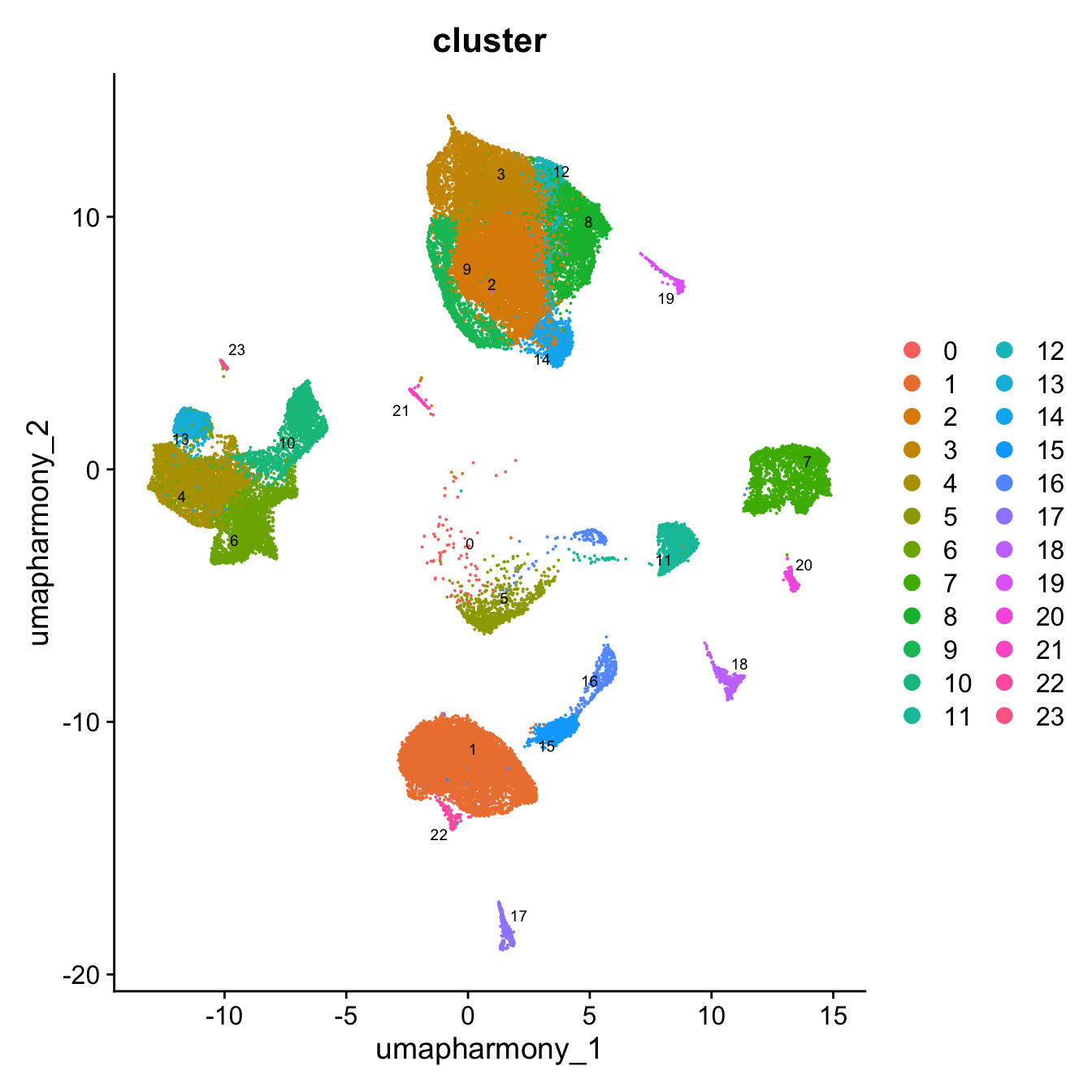
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
DimPlot(paed_other, reduction = "umap.harmony", label = TRUE, label.size = 2.5, repel = TRUE, raster = FALSE ) +NoLegend()Warning: ggrepel: 6 unlabeled data points (too many overlaps). Consider
increasing max.overlaps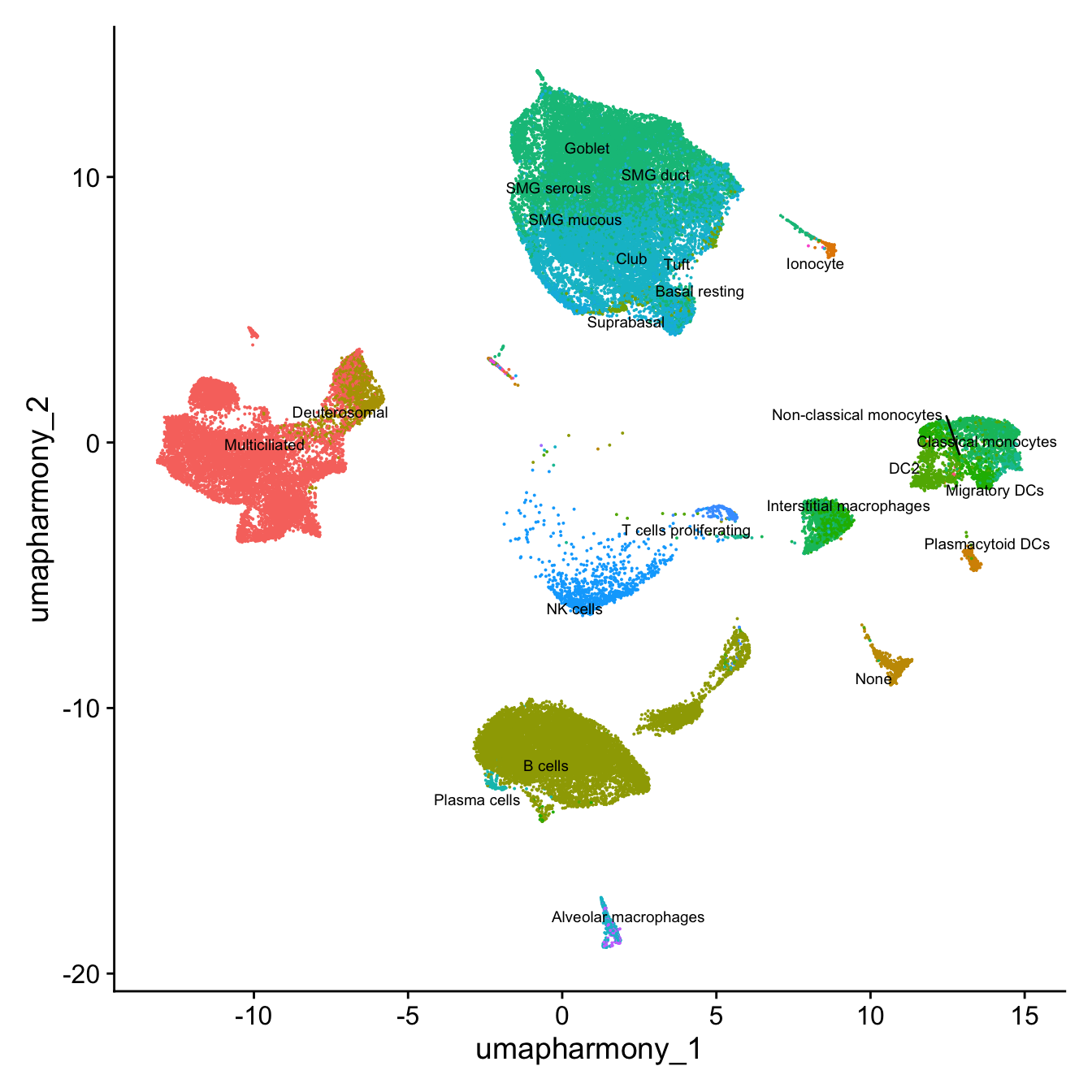
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
Save subclustered SEU object ( All other cells)
out2 <- here("output",
"RDS", "AllBatches_Subclustering_SEUs", tissue,
paste0("G000231_Neeland_",tissue,".all_other.subclusters.SEU.rds"))
#dir.create(out2)
if (!file.exists(out2)) {
saveRDS(paed_other, file = out2)
}Merge seurat objects of subclusters
files <- list.files(here("output",
"RDS", "AllBatches_Subclustering_SEUs", tissue),
full.names = TRUE)
seu_list <- lapply(files, function(f) readRDS(f))
seu <- merge(seu_list[[1]],
y = seu_list[[2]])
seuAn object of class Seurat
17973 features across 74812 samples within 1 assay
Active assay: RNA (17973 features, 2000 variable features)
6 layers present: data.1, data.2, counts.1, scale.data.1, counts.2, scale.data.2Exploring the contaminated B cell cluster in T cells
idx <- which(Idents(seu) %in% c("B cells", "plasma B cells", "contaminating B cell"))
paed_bcells <- seu[,idx]
paed_bcells <- paed_bcells %>%
NormalizeData() %>%
FindVariableFeatures() %>%
ScaleData() %>%
RunPCA()Normalizing layer: counts.1Normalizing layer: counts.2Finding variable features for layer counts.1Finding variable features for layer counts.2Centering and scaling data matrixPC_ 1
Positive: MEF2B, MKI67, RGS13, MYBL1, NUGGC, TOP2A, CDK1, TYMS, HMCES, DCAF12
CCNB2, UHRF1, AFF2, HJURP, HIST1H1B, MYBL2, CCDC88A, MME, BCL6, SEMA4A
CDC20, SPRED2, S1PR2, DEPDC1B, ASPM, CCNA2, SPC25, SYNE2, LOXL2, RAPGEF5
Negative: FCMR, B2M, TXNIP, KLF2, CD44, MPEG1, PARP15, SELL, PLAC8, IGHM
CCR6, FGD2, TNFRSF13B, PHACTR1, TRIM22, CAPG, EMP3, ZEB2, LY6E, CELF2
PLEKHO1, SPOCK2, TSC22D3, LIMD1, IGHD, COL19A1, P2RY10, RIPOR1, JUN, RIN3
PC_ 2
Positive: TCL1A, IGHM, IGHD, NIBAN3, MARCKSL1, DTX1, CD72, HMCES, BACH2, NEIL1
BCL7A, MEF2B, ELL3, MMP17, BCL6, MYBL1, NUGGC, MME, SEMA4A, CD200
LOXL2, RAPGEF5, VPREB3, KLHL14, SLC30A4, AFF2, H1FX, SPRED2, FCMR, SELL
Negative: ITGAX, FCRL4, KCTD12, TNFRSF13B, IFI30, CCR1, IL2RB, GSN, GRN, SIGLEC6
TESC, SEMA7A, BHLHE40, CCR5, VIM, BHLHE41, ITGB7, CD82, CTSH, PREX1
SOX5, IGHA1, THEMIS2, DUSP4, CAPG, HSPA6, TYMP, CCDC50, HCK, EFHD2
PC_ 3
Positive: MEF2B, LOXL2, SEMA4A, LMO2, RGS13, RAPGEF5, CAMK1, SPRED2, SERPINA9, HMCES
NEIL1, PTPRS, KLHL6, NUGGC, AFF2, EML6, BCL6, FGD6, SYNE2, MYO1E
ELL3, CCDC88A, S1PR2, LPP, HTR3A, P2RY12, MAML3, MME, CTSH, PLXNB2
Negative: TOP2A, MKI67, HIST1H1B, HJURP, CDK1, CDC20, CCNB2, TYMS, CCNA2, DLGAP5
HIST1H2BH, KIF23, DEPDC1B, ASPM, PLK1, SPC25, HMMR, AURKA, ANLN, CENPF
CENPE, KIF18B, TROAP, NEK2, HIST1H2BB, CDKN3, PBK, UBE2C, DEPDC1, CCNB1
PC_ 4
Positive: FCRL4, PLK1, TOP2A, HJURP, MKI67, ASPM, CDC20, KIF23, CCNB2, KCTD12
CDK1, HMMR, DLGAP5, CENPF, TROAP, IGHA2, DEPDC1B, AURKA, ANLN, IGHA1
KIF18B, UBE2C, KIF14, CCR5, KIF20A, CENPE, CCR1, GSN, CCNB1, ITGAX
Negative: CD83, EGR3, NR4A1, HSP90AB1, NFKBIA, CD72, KDM6B, DUSP2, CD69, NFKBID
ISG20, IGHM, JUNB, IL21R, NFKB2, IGHD, MYC, IFI44L, SOCS3, SRM
TRAF4, SYNGR2, SOD2, DDX21, NOP16, FOS, IFI44, G0S2, BIRC3, IFI6
PC_ 5
Positive: RESF1, CD48, B2M, DOCK10, CD24, DDX18, CLECL1, SAMSN1, CCR6, HNRNPU
PRDX1, RABGGTB, ODC1, IGHA2, GALNT1, SET, PARP15, CDV3, ZNF146, TRBC2
SESN3, MICOS10, TRAM1, CHCHD2, SPCS3, WDR3, CANX, MGAT4A, EIF3M, SPCS1
Negative: G0S2, CSF3R, PLAUR, FOSL2, CXCL8, FOS, DUSP1, AQP9, SOD2, NR4A1
NR4A2, ZFP36, IL1B, OSM, SOCS3, PPP1R15A, JUNB, NR4A3, FFAR2, ITGAX
IL1RN, FOSB, SLC11A1, PLK1, TSC22D3, KDM6B, HCAR3, TREM1, ISG20, NAMPT paed_bcells <- RunUMAP(paed_bcells, dims = 1:30, reduction = "pca", reduction.name = "umap.bcell")10:25:21 UMAP embedding parameters a = 0.9922 b = 1.112Found more than one class "dist" in cache; using the first, from namespace 'spam'Also defined by 'BiocGenerics'10:25:21 Read 11412 rows and found 30 numeric columns10:25:21 Using Annoy for neighbor search, n_neighbors = 30Found more than one class "dist" in cache; using the first, from namespace 'spam'Also defined by 'BiocGenerics'10:25:21 Building Annoy index with metric = cosine, n_trees = 500% 10 20 30 40 50 60 70 80 90 100%[----|----|----|----|----|----|----|----|----|----|**************************************************|
10:25:22 Writing NN index file to temp file /var/folders/q8/kw1r78g12qn793xm7g0zvk94x2bh70/T//RtmpewC7Yy/file5ed828118d09
10:25:22 Searching Annoy index using 1 thread, search_k = 3000
10:25:24 Annoy recall = 100%
10:25:24 Commencing smooth kNN distance calibration using 1 thread with target n_neighbors = 30
10:25:25 Initializing from normalized Laplacian + noise (using RSpectra)
10:25:25 Commencing optimization for 200 epochs, with 500484 positive edges
10:25:29 Optimization finishedDimPlot(paed_bcells, group.by = "cell_labels_v2",raster = FALSE, repel = TRUE, label = TRUE, label.size = 4.5)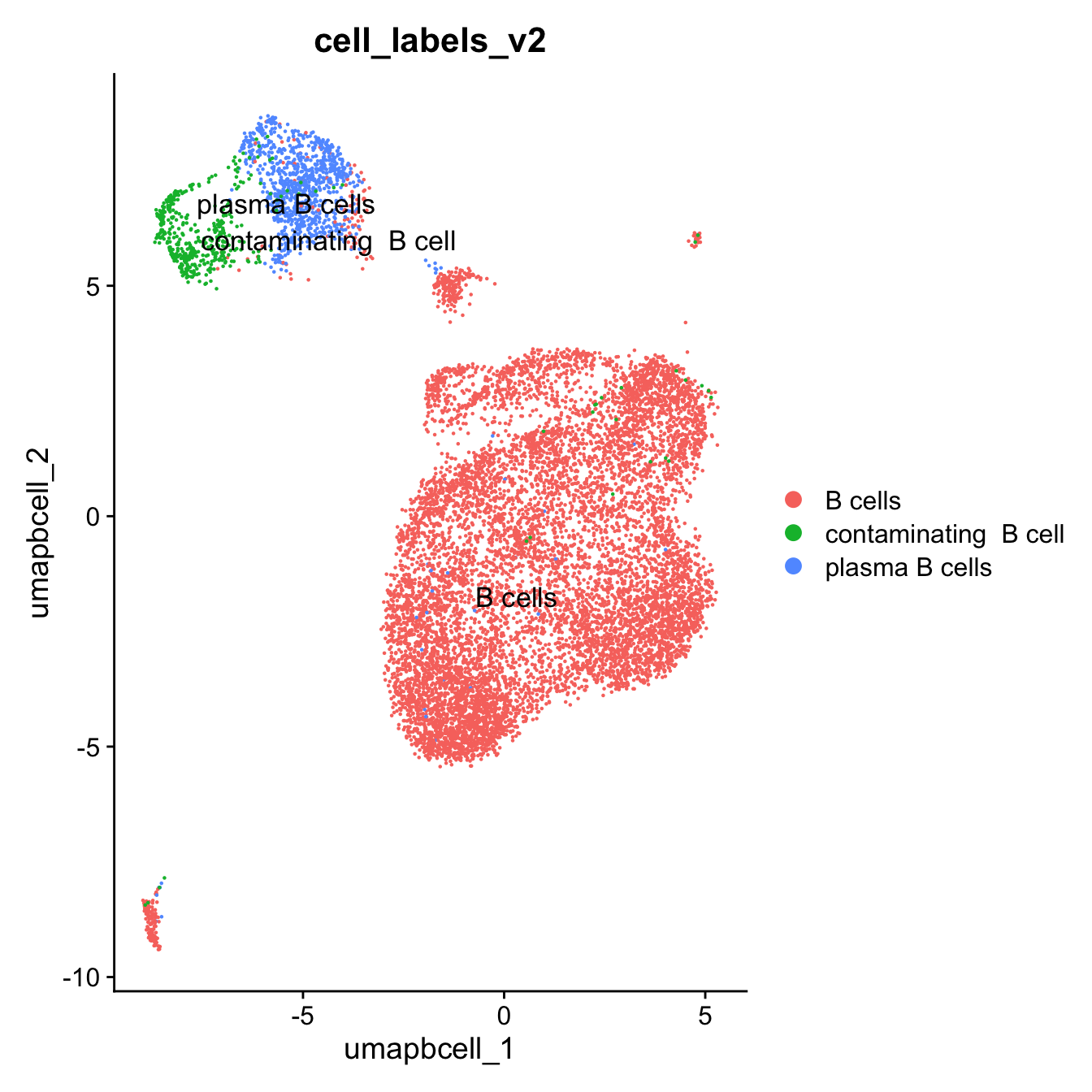
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
DimPlot(paed_bcells,raster = FALSE, repel = TRUE, label = TRUE, label.size = 4.5)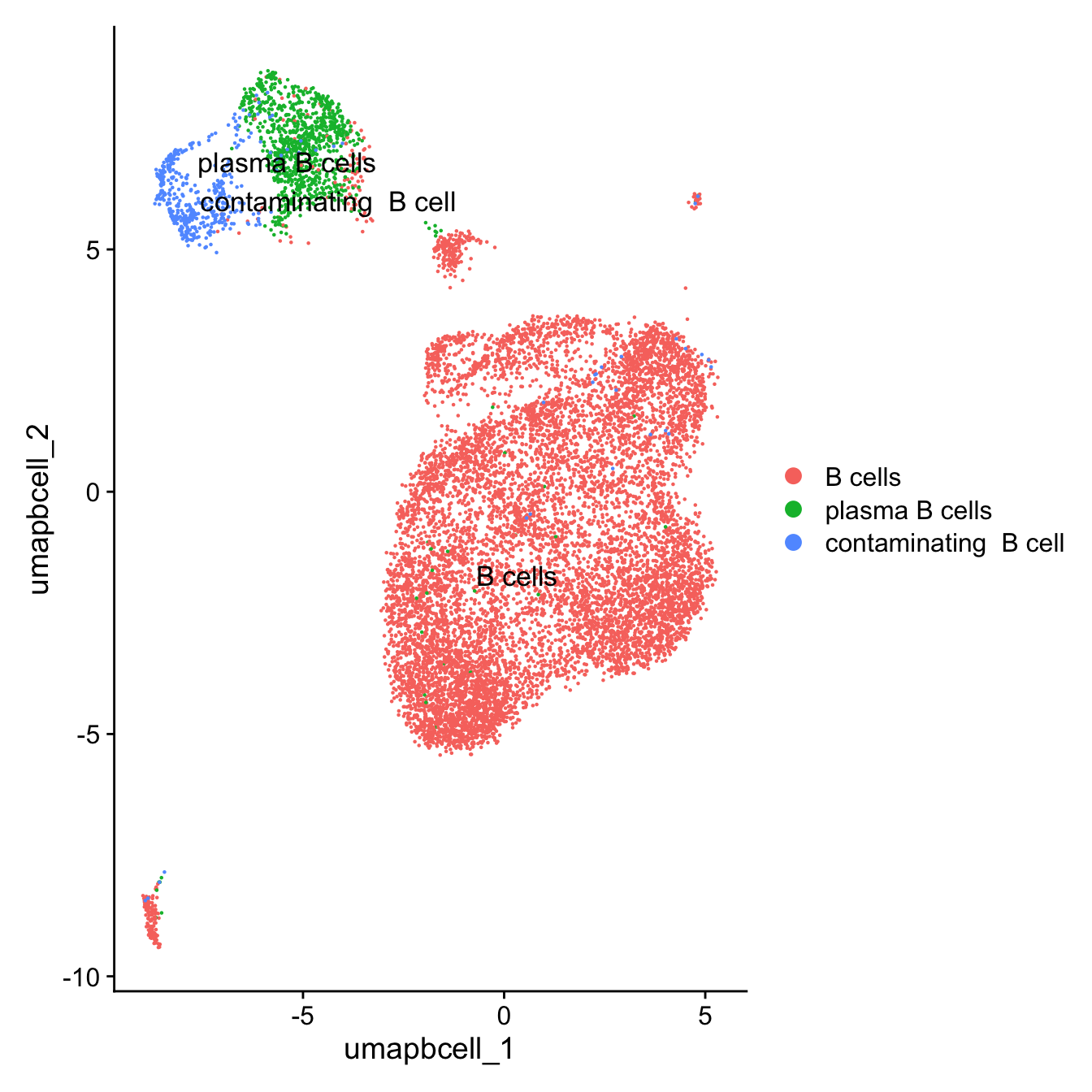
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
Reclustering B cells
The marker genes for this reclustering can be found here-
meta_data_columns <- colnames(paed_bcells@meta.data)
columns_to_remove <- grep("^RNA_snn_res", meta_data_columns, value = TRUE)
paed_bcells@meta.data <- paed_bcells@meta.data[, !(colnames(paed_bcells@meta.data) %in% columns_to_remove)]
resolutions <- seq(0.1, 1, by = 0.1)
paed_bcells <- FindNeighbors(paed_bcells, reduction = "pca", dims = 1:30)
paed_bcells <- FindClusters(paed_bcells, resolution = resolutions, algorithm = 3)Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.9359
Number of communities: 6
Elapsed time: 7 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.9066
Number of communities: 9
Elapsed time: 5 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8899
Number of communities: 10
Elapsed time: 6 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8732
Number of communities: 10
Elapsed time: 5 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8569
Number of communities: 11
Elapsed time: 5 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8430
Number of communities: 12
Elapsed time: 5 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8295
Number of communities: 12
Elapsed time: 5 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8162
Number of communities: 13
Elapsed time: 4 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.8051
Number of communities: 14
Elapsed time: 4 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11412
Number of edges: 378368
Running smart local moving algorithm...
Maximum modularity in 10 random starts: 0.7943
Number of communities: 15
Elapsed time: 4 secondsDimHeatmap(paed_bcells, dims = 1:10, cells = 500, balanced = TRUE)
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
clustree(paed_bcells, prefix = "RNA_snn_res.")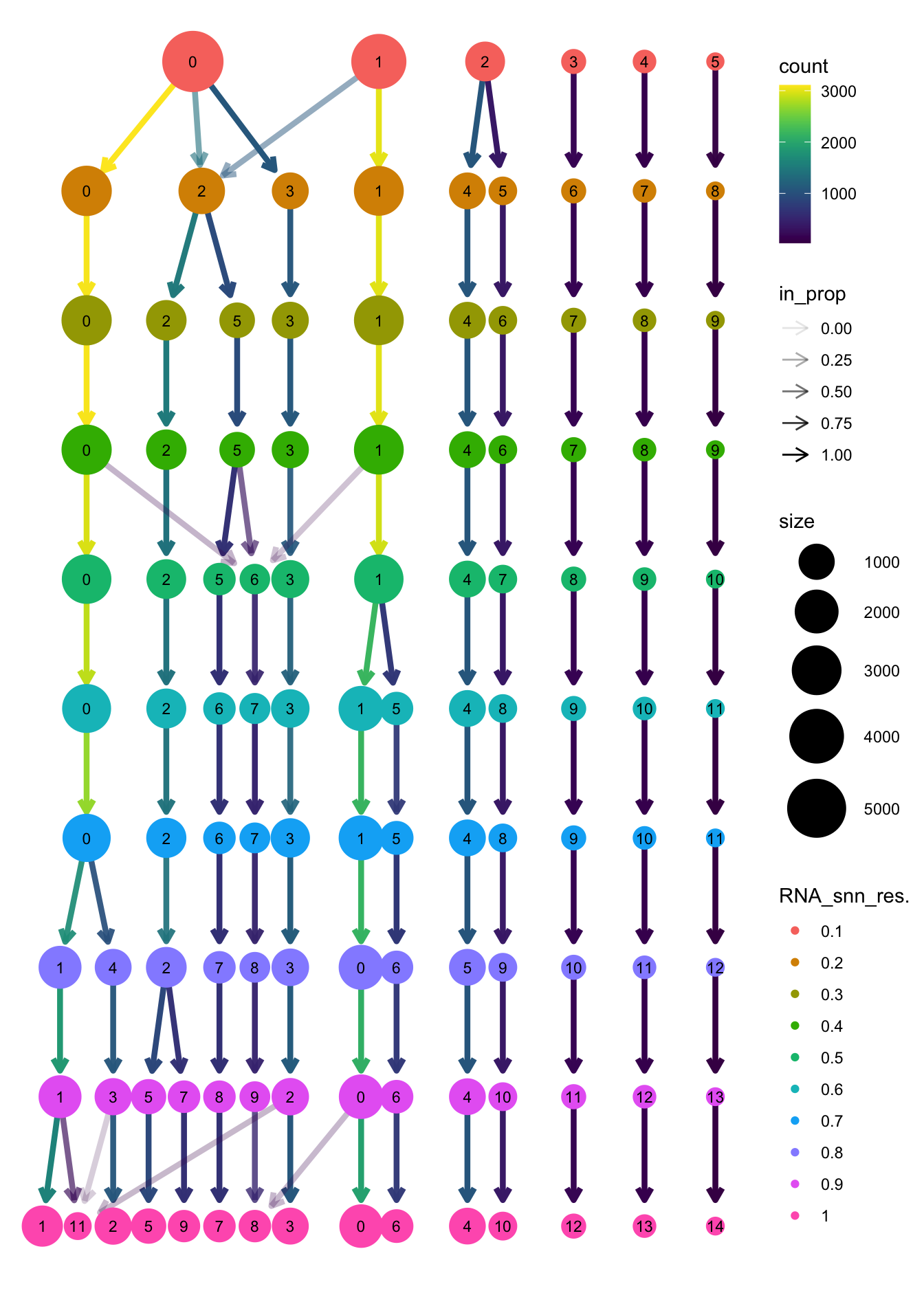
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
opt_res <- "RNA_snn_res.0.2"
n <- nlevels(paed_bcells$RNA_snn_res.0.2)
paed_bcells$RNA_snn_res.0.2 <- factor(paed_bcells$RNA_snn_res.0.2, levels = seq(0,n-1))
paed_bcells$seurat_clusters <- NULL
Idents(paed_bcells) <- paed_bcells$RNA_snn_res.0.2DimPlot(paed_bcells, group.by = "RNA_snn_res.0.2", label = TRUE, label.size = 4.5, repel = TRUE, raster = FALSE )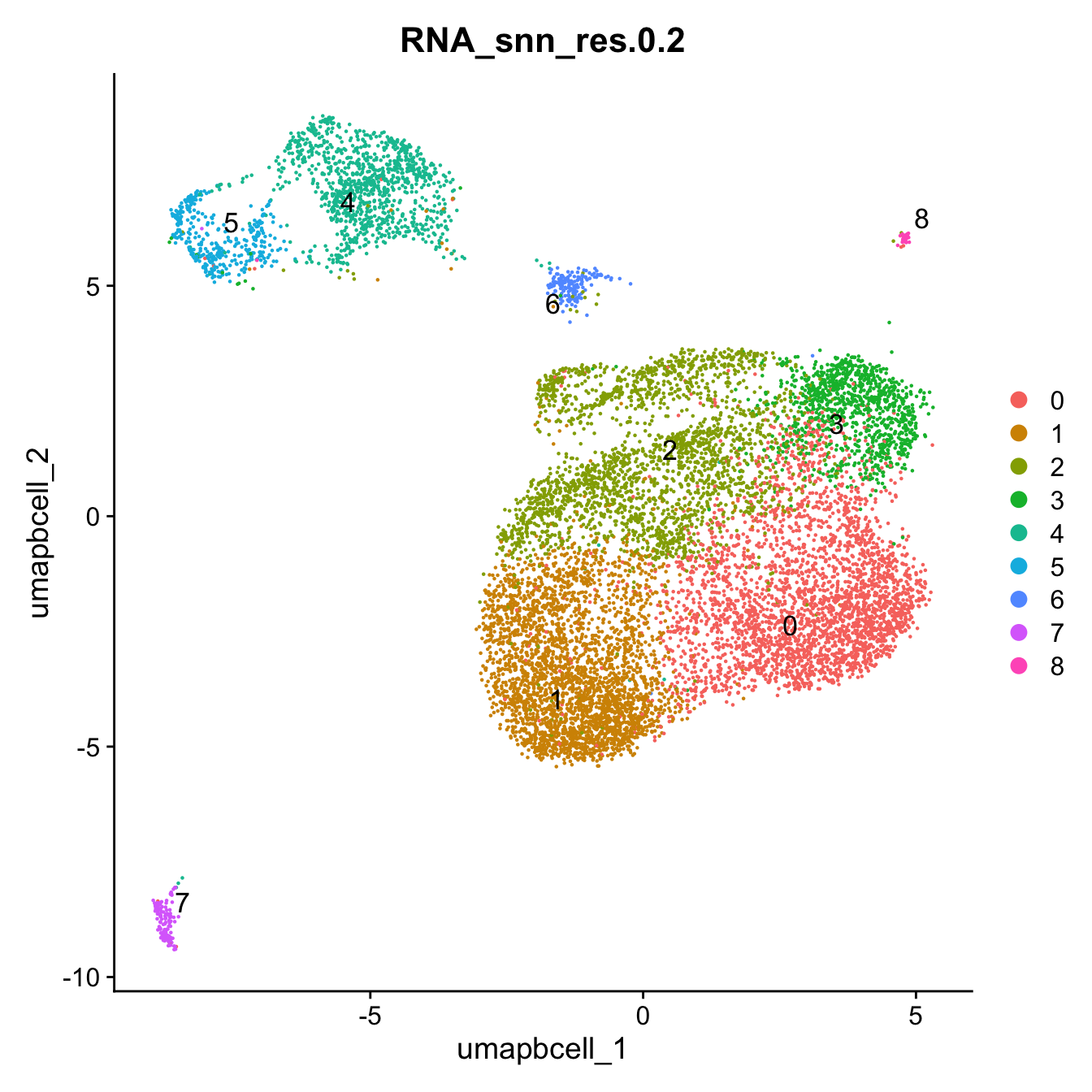
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
paed_bcells <- JoinLayers(paed_bcells)
paed_bcells.markers <- FindAllMarkers(paed_bcells, only.pos = TRUE, min.pct = 0.25, logfc.threshold = 0.25)Calculating cluster 0Calculating cluster 1Calculating cluster 2Calculating cluster 3Calculating cluster 4Calculating cluster 5Calculating cluster 6Calculating cluster 7Calculating cluster 8paed_bcells.markers %>%
group_by(cluster) %>% unique() %>%
top_n(n = 5, wt = avg_log2FC) -> top5
paed_bcells.markers %>%
group_by(cluster) %>%
slice_head(n=1) %>%
pull(gene) -> best.wilcox.gene.per.cluster
best.wilcox.gene.per.cluster[1] "B2M" "IGHD" "DUSP1" "ITGAX" "MEF2B" "HMGB2" "G0S2" "MZB1" "CD2" FeaturePlot(paed_bcells,features=best.wilcox.gene.per.cluster, raster = FALSE, label = T, ncol = 3)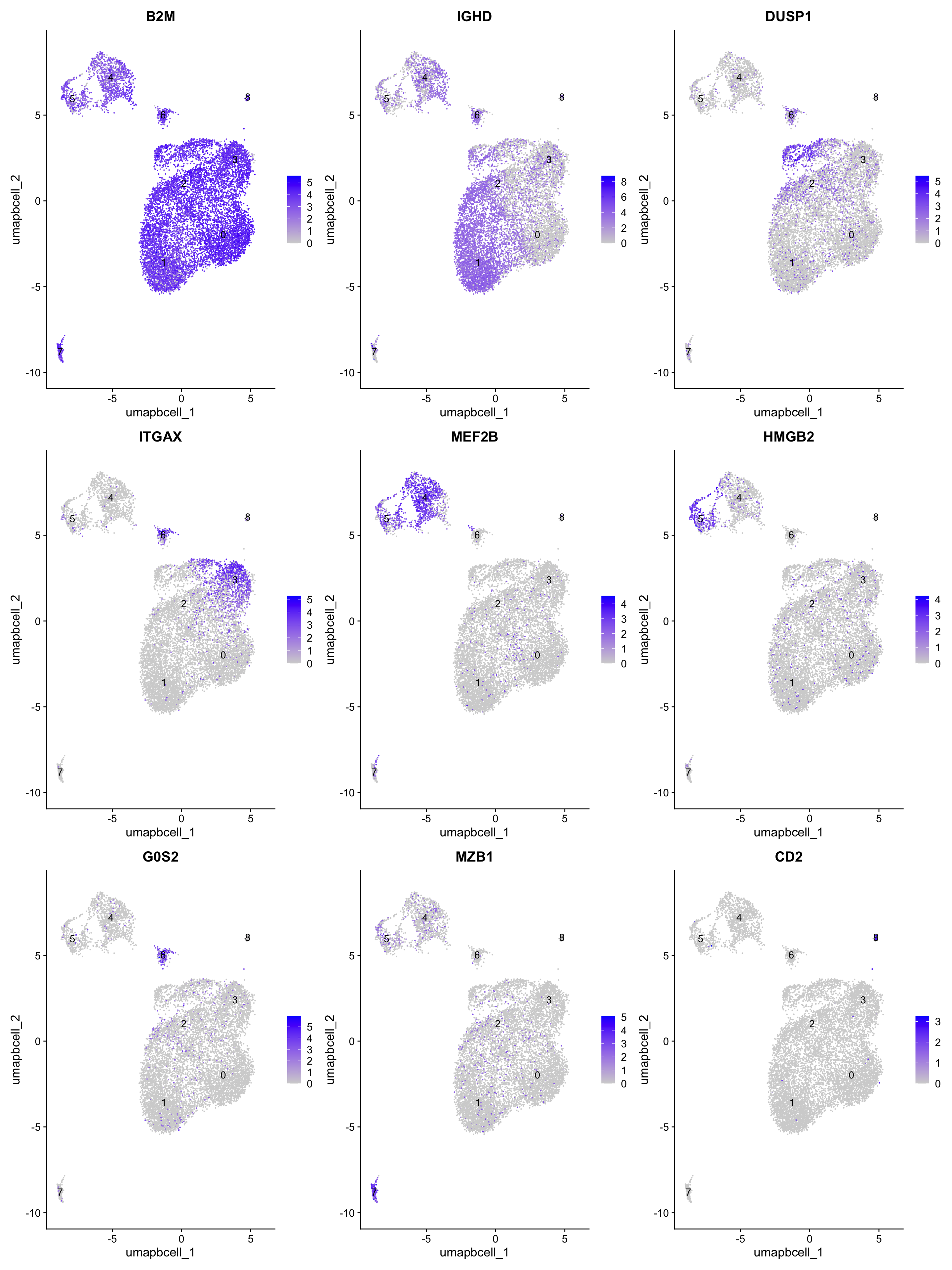
| Version | Author | Date |
|---|---|---|
| 07af966 | Gunjan Dixit | 2024-09-25 |
Top 10 marker genes from Seurat
## Seurat top markers
top10 <- paed_bcells.markers %>%
group_by(cluster) %>%
top_n(n = 10, wt = avg_log2FC) %>%
ungroup() %>%
distinct(gene, .keep_all = TRUE) %>%
arrange(cluster, desc(avg_log2FC))
cluster_colors <- paletteer::paletteer_d("pals::glasbey")[factor(top10$cluster)]
DotPlot(paed_bcells,
features = unique(top10$gene),
group.by = opt_res,
cols = c("azure1", "blueviolet"),
dot.scale = 3, assay = "RNA") +
RotatedAxis() +
FontSize(y.text = 8, x.text = 12) +
labs(y = element_blank(), x = element_blank()) +
coord_flip() +
theme(axis.text.y = element_text(color = cluster_colors)) +
ggtitle("Top 10 marker genes per cluster (Seurat)")Warning: Vectorized input to `element_text()` is not officially supported.
ℹ Results may be unexpected or may change in future versions of ggplot2.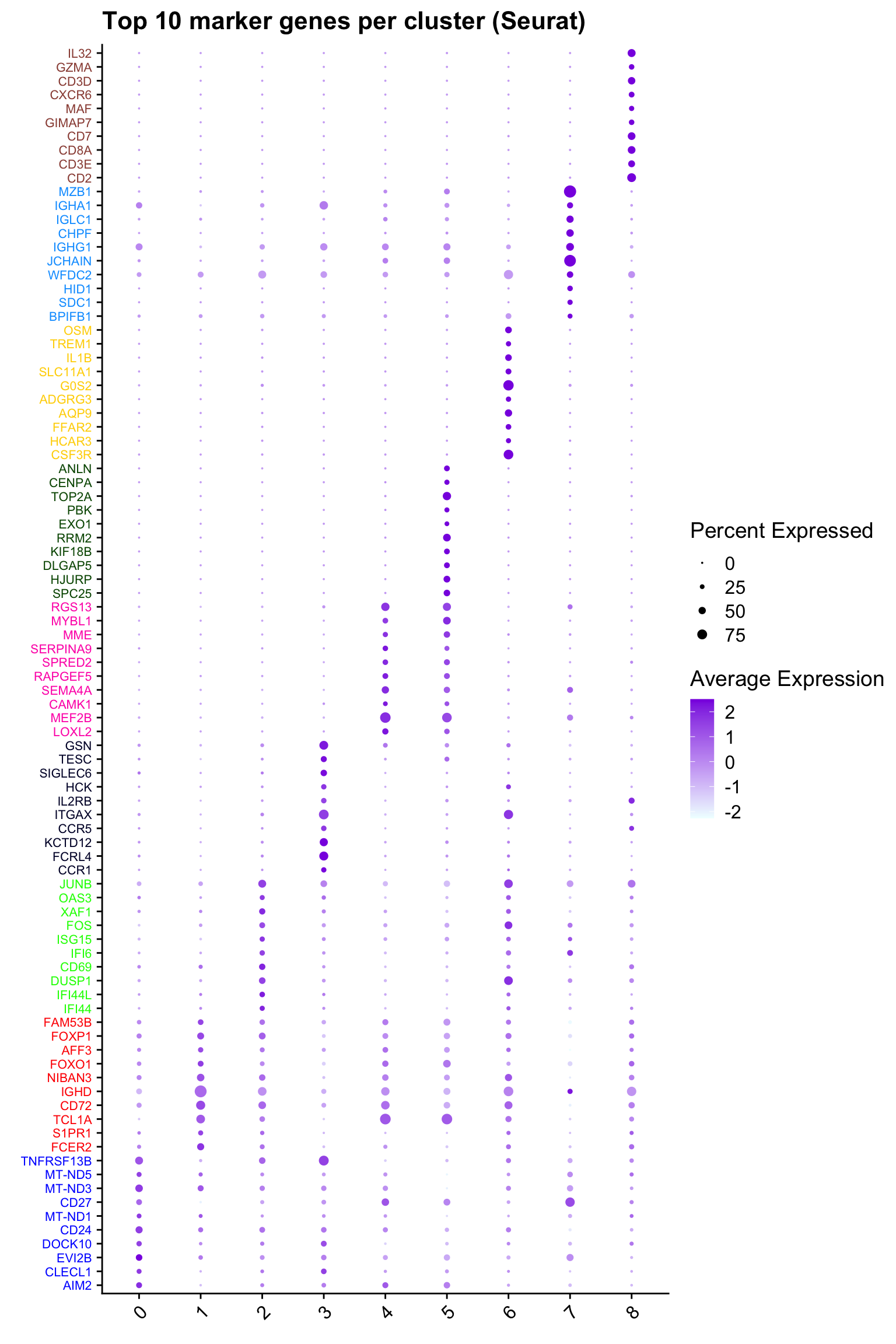
| Version | Author | Date |
|---|---|---|
| 952acbb | Gunjan Dixit | 2024-09-26 |
out_markers <- here("output",
"CSV",
paste(tissue,"_Marker_genes_Reclustered_Bcell_population.",opt_res, sep = ""))
dir.create(out_markers, recursive = TRUE, showWarnings = FALSE)
for (cl in unique(paed_bcells.markers$cluster)) {
cluster_data <- paed_bcells.markers %>% dplyr::filter(cluster == cl)
file_name <- here(out_markers, paste0("G000231_Neeland_",tissue, "_cluster_", cl, ".csv"))
if (!file.exists(file_name)) {
write.csv(cluster_data, file = file_name)
}
}Excluding contaminating labels
idx <- which(grepl("^contaminating", Idents(seu)))
seu <- seu[, -idx]merged <- seu %>%
NormalizeData() %>%
FindVariableFeatures() %>%
ScaleData() %>%
RunPCA()Normalizing layer: counts.1Normalizing layer: counts.2Finding variable features for layer counts.1Finding variable features for layer counts.2Centering and scaling data matrixPC_ 1
Positive: PIFO, ROPN1L, SNTN, RSPH4A, EFCAB1, CAPSL, FAM183A, SPA17, DNAH9, MORN2
C1orf194, CFAP126, CCDC65, ARMC3, C9orf135, FAM81B, ERICH3, CC2D2A, RSPH9, FAM216B
AKAP14, DRC1, AK7, NPHP1, LRRC23, CCN2, CCDC113, AGR3, CFAP206, MORN5
Negative: LCP1, ACTB, SRGN, TRBC2, CXCR4, COTL1, IL32, CCL5, LCP2, CD7
IL2RB, CNN2, CD2, LTB, CD8A, ITGB2, NKG7, ALOX5AP, VIM, TNFRSF1B
EMP3, CXCR6, SERPINB9, ZEB2, IRF8, FCMR, PRF1, TAGAP, CD79A, AOAH
PC_ 2
Positive: LCP1, VIM, TRBC2, CCL5, SRGN, COTL1, IL2RB, CD2, CD8A, CXCR4
LTB, CD7, NKG7, IL32, LCP2, CXCR6, ALOX5AP, PRF1, GZMA, FCMR
TRBC1, CD79A, ACTB, CCR5, CD69, ITGB2, AOAH, IGHM, IRF8, JAML
Negative: TACSTD2, SPINT1, MUC1, ASS1, SDC1, JUP, CAPN13, SCNN1A, TRIM29, PRSS8
ELF3, CLDN7, CEACAM5, ERN2, CDH3, ST14, PI3, ID1, MUC4, HS3ST1
CNN3, CLDN4, KLK11, CYP2F1, ARHGAP23, KIAA1522, PIGR, MYH14, BPIFA1, IDO1
PC_ 3
Positive: CCL5, TRBC2, CD8A, CD2, IL32, IL2RB, CXCR6, CD7, GZMA, TRBC1
ZNF683, PRF1, NKG7, KLRC4, HOPX, TIGIT, KLRD1, CTSW, FASLG, FCRL6
KLRC3, ITM2C, CD5, GNLY, FCMR, KLRC1, CST7, TCF7, GZMH, LDHB
Negative: LILRB2, CSF1R, FCER1G, CD14, CD163, SERPINA1, EMILIN2, TYROBP, AIF1, SLC8A1
LILRA5, MS4A6A, CD68, MAFB, FPR1, ADGRE2, STAB1, SPI1, TGFBI, CSF3R
PLAUR, APOBEC3A, MEFV, FCGR3A, TMEM176B, CSF2RA, VASH1, CTSL, CALHM6, ENPP2
PC_ 4
Positive: CEACAM5, CEACAM6, SLC26A4, MLPH, SPNS2, PI3, STEAP4, CYP2F1, FCGBP, TSPAN8
PIGR, ALPL, MSMB, ATP10B, TFF3, BPIFA1, SLURP2, TFF1, GDF15, CES1
DUOXA2, ERN2, DUOX2, BPIFB1, SDCBP2, RARRES1, SYT7, ECRG4, SLC9A3, IGFBP7
Negative: ANLN, CDC20, CDK1, TOP2A, KIFC1, MKI67, FOXM1, ZWINT, TYMS, CCNB2
DLGAP5, RRM2, KIF23, ASF1B, TPX2, BIRC5, CIT, TK1, KIF20A, NEK2
SPC24, E2F7, BUB1, HJURP, POC1A, STMN1, CDCA5, CENPF, HIST1H1B, KIF2C
PC_ 5
Positive: CD79A, IGHM, IGKC, IRF8, IGHD, BCL11A, POU2AF1, FCRL5, SPIB, BLK
MPEG1, CLEC17A, TCL1A, TNFRSF13B, CXCR5, RASGRP2, CR1, CYBB, CD83, IGHG1
LTB, CR2, PLCG2, AFF3, LRMP, FCMR, CTSH, CCR6, IGHA1, SELL
Negative: CCL5, IL32, CD7, NKG7, CD8A, IL2RB, PRF1, CXCR6, CD2, GZMA
LAG3, LCP2, ZNF683, KLRD1, KLRC4, GNLY, GZMB, CST7, CTSW, AOAH
FASLG, TRBC1, SRGN, CCR5, CSF1, JAML, TRBC2, HOPX, KLRC3, TIGIT merged <- RunUMAP(merged, dims = 1:30, reduction = "pca", reduction.name = "umap.merged")10:27:32 UMAP embedding parameters a = 0.9922 b = 1.112Found more than one class "dist" in cache; using the first, from namespace 'spam'Also defined by 'BiocGenerics'10:27:32 Read 74353 rows and found 30 numeric columns10:27:32 Using Annoy for neighbor search, n_neighbors = 30Found more than one class "dist" in cache; using the first, from namespace 'spam'Also defined by 'BiocGenerics'10:27:32 Building Annoy index with metric = cosine, n_trees = 500% 10 20 30 40 50 60 70 80 90 100%[----|----|----|----|----|----|----|----|----|----|**************************************************|
10:27:36 Writing NN index file to temp file /var/folders/q8/kw1r78g12qn793xm7g0zvk94x2bh70/T//RtmpewC7Yy/file5ed81d4ce01e
10:27:36 Searching Annoy index using 1 thread, search_k = 3000
10:27:50 Annoy recall = 100%
10:27:50 Commencing smooth kNN distance calibration using 1 thread with target n_neighbors = 30
10:27:52 Initializing from normalized Laplacian + noise (using RSpectra)
10:28:06 Commencing optimization for 200 epochs, with 3225212 positive edges
10:28:28 Optimization finishedp4 <- DimPlot(merged, reduction = "umap.merged", group.by = "cell_labels_v2",raster = FALSE, repel = TRUE, label = TRUE, label.size = 4.5) + ggtitle(paste0(tissue, ": UMAP with annotations")) + NoLegend()
p4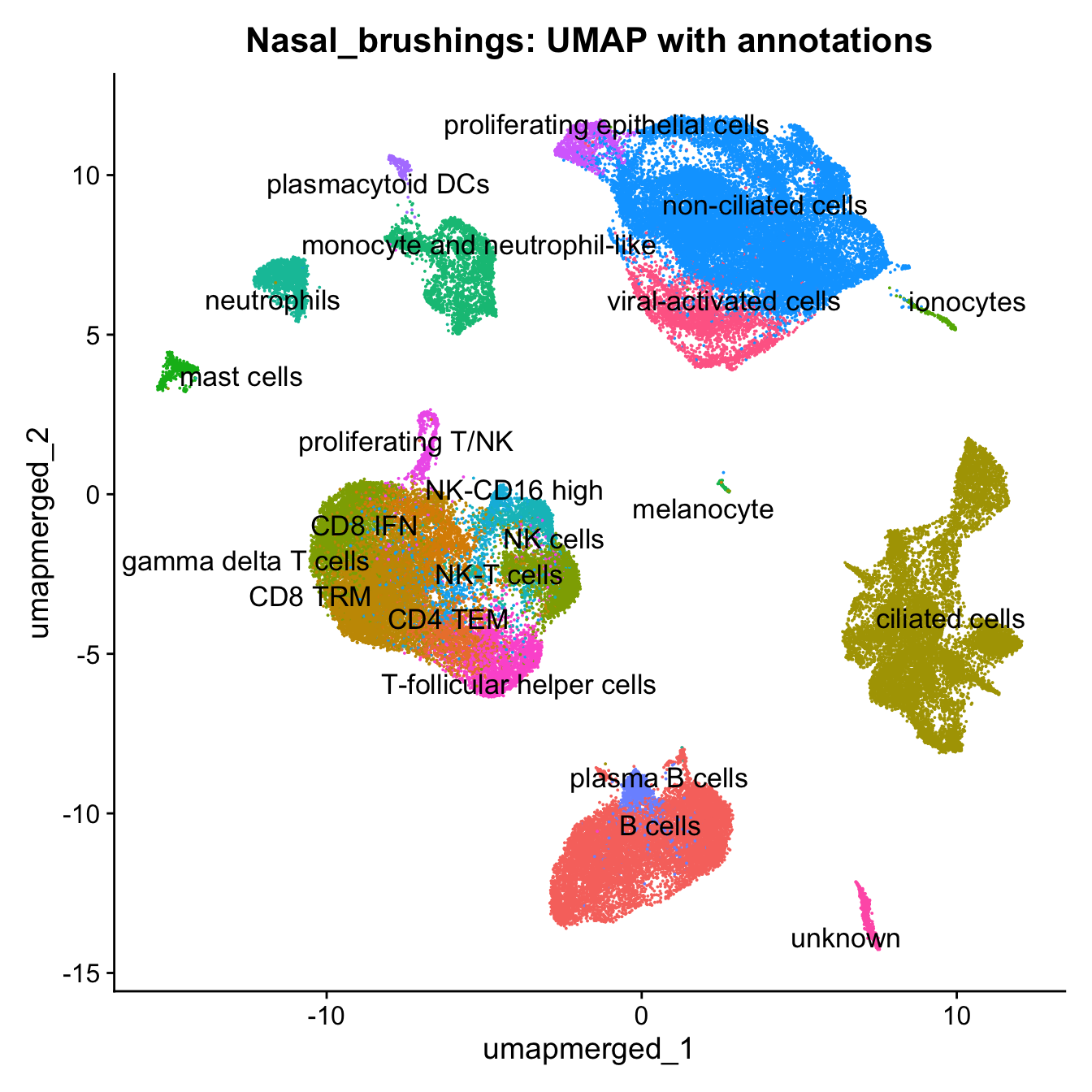
| Version | Author | Date |
|---|---|---|
| 952acbb | Gunjan Dixit | 2024-09-26 |
Save Final SEU object (All cells)
out3 <- here("output",
"RDS", "AllBatches_Final_Clusters_SEUs",
paste0("G000231_Neeland_",tissue,".final_clusters.SEU.rds"))
if (!file.exists(out3)) {
saveRDS(merged, file = out3)
}Session Info
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.3.2 (2023-10-31)
os macOS Sonoma 14.6.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Australia/Melbourne
date 2024-09-26
pandoc 3.1.1 @ /Users/dixitgunjan/Desktop/RStudio.app/Contents/Resources/app/quarto/bin/tools/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
abind 1.4-5 2016-07-21 [1] CRAN (R 4.3.0)
AnnotationDbi * 1.64.1 2023-11-02 [1] Bioconductor
backports 1.4.1 2021-12-13 [1] CRAN (R 4.3.0)
Biobase * 2.62.0 2023-10-26 [1] Bioconductor
BiocGenerics * 0.48.1 2023-11-02 [1] Bioconductor
BiocManager 1.30.22 2023-08-08 [1] CRAN (R 4.3.0)
BiocStyle * 2.30.0 2023-10-26 [1] Bioconductor
Biostrings 2.70.2 2024-01-30 [1] Bioconductor 3.18 (R 4.3.2)
bit 4.0.5 2022-11-15 [1] CRAN (R 4.3.0)
bit64 4.0.5 2020-08-30 [1] CRAN (R 4.3.0)
bitops 1.0-7 2021-04-24 [1] CRAN (R 4.3.0)
blob 1.2.4 2023-03-17 [1] CRAN (R 4.3.0)
bslib 0.6.1 2023-11-28 [1] CRAN (R 4.3.1)
cachem 1.0.8 2023-05-01 [1] CRAN (R 4.3.0)
callr 3.7.5 2024-02-19 [1] CRAN (R 4.3.1)
cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.3.0)
checkmate 2.3.1 2023-12-04 [1] CRAN (R 4.3.1)
cli 3.6.2 2023-12-11 [1] CRAN (R 4.3.1)
cluster 2.1.6 2023-12-01 [1] CRAN (R 4.3.1)
clustree * 0.5.1 2023-11-05 [1] CRAN (R 4.3.1)
codetools 0.2-19 2023-02-01 [1] CRAN (R 4.3.2)
colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)
cowplot 1.1.3 2024-01-22 [1] CRAN (R 4.3.1)
crayon 1.5.2 2022-09-29 [1] CRAN (R 4.3.0)
data.table * 1.15.0 2024-01-30 [1] CRAN (R 4.3.1)
DBI 1.2.2 2024-02-16 [1] CRAN (R 4.3.1)
DelayedArray 0.28.0 2023-11-06 [1] Bioconductor
deldir 2.0-2 2023-11-23 [1] CRAN (R 4.3.1)
digest 0.6.34 2024-01-11 [1] CRAN (R 4.3.1)
dotCall64 1.1-1 2023-11-28 [1] CRAN (R 4.3.1)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.3.1)
edgeR * 4.0.16 2024-02-20 [1] Bioconductor 3.18 (R 4.3.2)
ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.3.0)
evaluate 0.23 2023-11-01 [1] CRAN (R 4.3.1)
fansi 1.0.6 2023-12-08 [1] CRAN (R 4.3.1)
farver 2.1.1 2022-07-06 [1] CRAN (R 4.3.0)
fastDummies 1.7.3 2023-07-06 [1] CRAN (R 4.3.0)
fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)
fitdistrplus 1.1-11 2023-04-25 [1] CRAN (R 4.3.0)
forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)
fs 1.6.3 2023-07-20 [1] CRAN (R 4.3.0)
future 1.33.1 2023-12-22 [1] CRAN (R 4.3.1)
future.apply 1.11.1 2023-12-21 [1] CRAN (R 4.3.1)
generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)
GenomeInfoDb 1.38.6 2024-02-10 [1] Bioconductor 3.18 (R 4.3.2)
GenomeInfoDbData 1.2.11 2024-02-27 [1] Bioconductor
GenomicRanges 1.54.1 2023-10-30 [1] Bioconductor
getPass 0.2-4 2023-12-10 [1] CRAN (R 4.3.1)
ggforce 0.4.2 2024-02-19 [1] CRAN (R 4.3.1)
ggplot2 * 3.5.0 2024-02-23 [1] CRAN (R 4.3.1)
ggraph * 2.1.0 2022-10-09 [1] CRAN (R 4.3.0)
ggrepel 0.9.5 2024-01-10 [1] CRAN (R 4.3.1)
ggridges 0.5.6 2024-01-23 [1] CRAN (R 4.3.1)
git2r 0.33.0 2023-11-26 [1] CRAN (R 4.3.1)
globals 0.16.2 2022-11-21 [1] CRAN (R 4.3.0)
glue * 1.7.0 2024-01-09 [1] CRAN (R 4.3.1)
goftest 1.2-3 2021-10-07 [1] CRAN (R 4.3.0)
graphlayouts 1.1.0 2024-01-19 [1] CRAN (R 4.3.1)
gridExtra 2.3 2017-09-09 [1] CRAN (R 4.3.0)
gtable 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)
here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)
highr 0.10 2022-12-22 [1] CRAN (R 4.3.0)
hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)
htmltools 0.5.7 2023-11-03 [1] CRAN (R 4.3.1)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.3.1)
httpuv 1.6.14 2024-01-26 [1] CRAN (R 4.3.1)
httr 1.4.7 2023-08-15 [1] CRAN (R 4.3.0)
ica 1.0-3 2022-07-08 [1] CRAN (R 4.3.0)
igraph 2.0.2 2024-02-17 [1] CRAN (R 4.3.1)
IRanges * 2.36.0 2023-10-26 [1] Bioconductor
irlba 2.3.5.1 2022-10-03 [1] CRAN (R 4.3.2)
jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.3.0)
jsonlite 1.8.8 2023-12-04 [1] CRAN (R 4.3.1)
kableExtra * 1.4.0 2024-01-24 [1] CRAN (R 4.3.1)
KEGGREST 1.42.0 2023-10-26 [1] Bioconductor
KernSmooth 2.23-22 2023-07-10 [1] CRAN (R 4.3.2)
knitr 1.45 2023-10-30 [1] CRAN (R 4.3.1)
labeling 0.4.3 2023-08-29 [1] CRAN (R 4.3.0)
later 1.3.2 2023-12-06 [1] CRAN (R 4.3.1)
lattice 0.22-5 2023-10-24 [1] CRAN (R 4.3.1)
lazyeval 0.2.2 2019-03-15 [1] CRAN (R 4.3.0)
leiden 0.4.3.1 2023-11-17 [1] CRAN (R 4.3.1)
lifecycle 1.0.4 2023-11-07 [1] CRAN (R 4.3.1)
limma * 3.58.1 2023-11-02 [1] Bioconductor
listenv 0.9.1 2024-01-29 [1] CRAN (R 4.3.1)
lmtest 0.9-40 2022-03-21 [1] CRAN (R 4.3.0)
locfit 1.5-9.8 2023-06-11 [1] CRAN (R 4.3.0)
lubridate * 1.9.3 2023-09-27 [1] CRAN (R 4.3.1)
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)
MASS 7.3-60.0.1 2024-01-13 [1] CRAN (R 4.3.1)
Matrix 1.6-5 2024-01-11 [1] CRAN (R 4.3.1)
MatrixGenerics 1.14.0 2023-10-26 [1] Bioconductor
matrixStats 1.2.0 2023-12-11 [1] CRAN (R 4.3.1)
memoise 2.0.1 2021-11-26 [1] CRAN (R 4.3.0)
mime 0.12 2021-09-28 [1] CRAN (R 4.3.0)
miniUI 0.1.1.1 2018-05-18 [1] CRAN (R 4.3.0)
munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)
nlme 3.1-164 2023-11-27 [1] CRAN (R 4.3.1)
org.Hs.eg.db * 3.18.0 2024-02-27 [1] Bioconductor
paletteer 1.6.0 2024-01-21 [1] CRAN (R 4.3.1)
parallelly 1.37.0 2024-02-14 [1] CRAN (R 4.3.1)
patchwork * 1.2.0 2024-01-08 [1] CRAN (R 4.3.1)
pbapply 1.7-2 2023-06-27 [1] CRAN (R 4.3.0)
pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)
plotly 4.10.4 2024-01-13 [1] CRAN (R 4.3.1)
plyr 1.8.9 2023-10-02 [1] CRAN (R 4.3.1)
png 0.1-8 2022-11-29 [1] CRAN (R 4.3.0)
polyclip 1.10-6 2023-09-27 [1] CRAN (R 4.3.1)
presto 1.0.0 2024-02-27 [1] Github (immunogenomics/presto@31dc97f)
prismatic 1.1.1 2022-08-15 [1] CRAN (R 4.3.0)
processx 3.8.3 2023-12-10 [1] CRAN (R 4.3.1)
progressr 0.14.0 2023-08-10 [1] CRAN (R 4.3.0)
promises 1.2.1 2023-08-10 [1] CRAN (R 4.3.0)
ps 1.7.6 2024-01-18 [1] CRAN (R 4.3.1)
purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)
R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)
RANN 2.6.1 2019-01-08 [1] CRAN (R 4.3.0)
RColorBrewer * 1.1-3 2022-04-03 [1] CRAN (R 4.3.0)
Rcpp 1.0.12 2024-01-09 [1] CRAN (R 4.3.1)
RcppAnnoy 0.0.22 2024-01-23 [1] CRAN (R 4.3.1)
RcppHNSW 0.6.0 2024-02-04 [1] CRAN (R 4.3.1)
RCurl 1.98-1.14 2024-01-09 [1] CRAN (R 4.3.1)
readr * 2.1.5 2024-01-10 [1] CRAN (R 4.3.1)
readxl * 1.4.3 2023-07-06 [1] CRAN (R 4.3.0)
rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.3.0)
reshape2 1.4.4 2020-04-09 [1] CRAN (R 4.3.0)
reticulate 1.35.0 2024-01-31 [1] CRAN (R 4.3.1)
rlang 1.1.3 2024-01-10 [1] CRAN (R 4.3.1)
rmarkdown 2.25 2023-09-18 [1] CRAN (R 4.3.1)
ROCR 1.0-11 2020-05-02 [1] CRAN (R 4.3.0)
rprojroot 2.0.4 2023-11-05 [1] CRAN (R 4.3.1)
RSpectra 0.16-1 2022-04-24 [1] CRAN (R 4.3.0)
RSQLite 2.3.5 2024-01-21 [1] CRAN (R 4.3.1)
rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)
Rtsne 0.17 2023-12-07 [1] CRAN (R 4.3.1)
S4Arrays 1.2.0 2023-10-26 [1] Bioconductor
S4Vectors * 0.40.2 2023-11-25 [1] Bioconductor 3.18 (R 4.3.2)
sass 0.4.8 2023-12-06 [1] CRAN (R 4.3.1)
scales 1.3.0 2023-11-28 [1] CRAN (R 4.3.1)
scattermore 1.2 2023-06-12 [1] CRAN (R 4.3.0)
sctransform 0.4.1 2023-10-19 [1] CRAN (R 4.3.1)
sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)
Seurat * 5.0.1.9009 2024-02-28 [1] Github (satijalab/seurat@6a3ef5e)
SeuratObject * 5.0.1 2023-11-17 [1] CRAN (R 4.3.1)
shiny 1.8.0 2023-11-17 [1] CRAN (R 4.3.1)
SingleCellExperiment 1.24.0 2023-11-06 [1] Bioconductor
sp * 2.1-3 2024-01-30 [1] CRAN (R 4.3.1)
spam 2.10-0 2023-10-23 [1] CRAN (R 4.3.1)
SparseArray 1.2.4 2024-02-10 [1] Bioconductor 3.18 (R 4.3.2)
spatstat.data 3.0-4 2024-01-15 [1] CRAN (R 4.3.1)
spatstat.explore 3.2-6 2024-02-01 [1] CRAN (R 4.3.1)
spatstat.geom 3.2-8 2024-01-26 [1] CRAN (R 4.3.1)
spatstat.random 3.2-2 2023-11-29 [1] CRAN (R 4.3.1)
spatstat.sparse 3.0-3 2023-10-24 [1] CRAN (R 4.3.1)
spatstat.utils 3.0-4 2023-10-24 [1] CRAN (R 4.3.1)
speckle * 1.2.0 2023-10-26 [1] Bioconductor
statmod 1.5.0 2023-01-06 [1] CRAN (R 4.3.0)
stringi 1.8.3 2023-12-11 [1] CRAN (R 4.3.1)
stringr * 1.5.1 2023-11-14 [1] CRAN (R 4.3.1)
SummarizedExperiment 1.32.0 2023-11-06 [1] Bioconductor
survival 3.5-8 2024-02-14 [1] CRAN (R 4.3.1)
svglite 2.1.3 2023-12-08 [1] CRAN (R 4.3.1)
systemfonts 1.0.5 2023-10-09 [1] CRAN (R 4.3.1)
tensor 1.5 2012-05-05 [1] CRAN (R 4.3.0)
tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)
tidygraph 1.3.1 2024-01-30 [1] CRAN (R 4.3.1)
tidyr * 1.3.1 2024-01-24 [1] CRAN (R 4.3.1)
tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)
tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)
timechange 0.3.0 2024-01-18 [1] CRAN (R 4.3.1)
tweenr 2.0.3 2024-02-26 [1] CRAN (R 4.3.1)
tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)
utf8 1.2.4 2023-10-22 [1] CRAN (R 4.3.1)
uwot 0.1.16 2023-06-29 [1] CRAN (R 4.3.0)
vctrs 0.6.5 2023-12-01 [1] CRAN (R 4.3.1)
viridis 0.6.5 2024-01-29 [1] CRAN (R 4.3.1)
viridisLite 0.4.2 2023-05-02 [1] CRAN (R 4.3.0)
whisker 0.4.1 2022-12-05 [1] CRAN (R 4.3.0)
withr 3.0.0 2024-01-16 [1] CRAN (R 4.3.1)
workflowr * 1.7.1 2023-08-23 [1] CRAN (R 4.3.0)
xfun 0.42 2024-02-08 [1] CRAN (R 4.3.1)
xml2 1.3.6 2023-12-04 [1] CRAN (R 4.3.1)
xtable 1.8-4 2019-04-21 [1] CRAN (R 4.3.0)
XVector 0.42.0 2023-10-26 [1] Bioconductor
yaml 2.3.8 2023-12-11 [1] CRAN (R 4.3.1)
zlibbioc 1.48.0 2023-10-26 [1] Bioconductor
zoo 1.8-12 2023-04-13 [1] CRAN (R 4.3.0)
[1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library
──────────────────────────────────────────────────────────────────────────────
sessionInfo()R version 4.3.2 (2023-10-31)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.6.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Australia/Melbourne
tzcode source: internal
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] readxl_1.4.3 org.Hs.eg.db_3.18.0 AnnotationDbi_1.64.1
[4] IRanges_2.36.0 S4Vectors_0.40.2 Biobase_2.62.0
[7] BiocGenerics_0.48.1 speckle_1.2.0 edgeR_4.0.16
[10] limma_3.58.1 patchwork_1.2.0 data.table_1.15.0
[13] RColorBrewer_1.1-3 kableExtra_1.4.0 clustree_0.5.1
[16] ggraph_2.1.0 Seurat_5.0.1.9009 SeuratObject_5.0.1
[19] sp_2.1-3 glue_1.7.0 here_1.0.1
[22] lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1
[25] dplyr_1.1.4 purrr_1.0.2 readr_2.1.5
[28] tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.0
[31] tidyverse_2.0.0 BiocStyle_2.30.0 workflowr_1.7.1
loaded via a namespace (and not attached):
[1] fs_1.6.3 matrixStats_1.2.0
[3] spatstat.sparse_3.0-3 bitops_1.0-7
[5] httr_1.4.7 tools_4.3.2
[7] sctransform_0.4.1 backports_1.4.1
[9] utf8_1.2.4 R6_2.5.1
[11] lazyeval_0.2.2 uwot_0.1.16
[13] withr_3.0.0 gridExtra_2.3
[15] progressr_0.14.0 cli_3.6.2
[17] spatstat.explore_3.2-6 fastDummies_1.7.3
[19] prismatic_1.1.1 labeling_0.4.3
[21] sass_0.4.8 spatstat.data_3.0-4
[23] ggridges_0.5.6 pbapply_1.7-2
[25] systemfonts_1.0.5 svglite_2.1.3
[27] sessioninfo_1.2.2 parallelly_1.37.0
[29] rstudioapi_0.15.0 RSQLite_2.3.5
[31] generics_0.1.3 ica_1.0-3
[33] spatstat.random_3.2-2 Matrix_1.6-5
[35] fansi_1.0.6 abind_1.4-5
[37] lifecycle_1.0.4 whisker_0.4.1
[39] yaml_2.3.8 SummarizedExperiment_1.32.0
[41] SparseArray_1.2.4 Rtsne_0.17
[43] paletteer_1.6.0 grid_4.3.2
[45] blob_1.2.4 promises_1.2.1
[47] crayon_1.5.2 miniUI_0.1.1.1
[49] lattice_0.22-5 cowplot_1.1.3
[51] KEGGREST_1.42.0 pillar_1.9.0
[53] knitr_1.45 GenomicRanges_1.54.1
[55] future.apply_1.11.1 codetools_0.2-19
[57] leiden_0.4.3.1 getPass_0.2-4
[59] vctrs_0.6.5 png_0.1-8
[61] spam_2.10-0 cellranger_1.1.0
[63] gtable_0.3.4 rematch2_2.1.2
[65] cachem_1.0.8 xfun_0.42
[67] S4Arrays_1.2.0 mime_0.12
[69] tidygraph_1.3.1 survival_3.5-8
[71] SingleCellExperiment_1.24.0 statmod_1.5.0
[73] ellipsis_0.3.2 fitdistrplus_1.1-11
[75] ROCR_1.0-11 nlme_3.1-164
[77] bit64_4.0.5 RcppAnnoy_0.0.22
[79] GenomeInfoDb_1.38.6 rprojroot_2.0.4
[81] bslib_0.6.1 irlba_2.3.5.1
[83] KernSmooth_2.23-22 colorspace_2.1-0
[85] DBI_1.2.2 tidyselect_1.2.0
[87] processx_3.8.3 bit_4.0.5
[89] compiler_4.3.2 git2r_0.33.0
[91] xml2_1.3.6 DelayedArray_0.28.0
[93] plotly_4.10.4 checkmate_2.3.1
[95] scales_1.3.0 lmtest_0.9-40
[97] callr_3.7.5 digest_0.6.34
[99] goftest_1.2-3 spatstat.utils_3.0-4
[101] presto_1.0.0 rmarkdown_2.25
[103] XVector_0.42.0 htmltools_0.5.7
[105] pkgconfig_2.0.3 MatrixGenerics_1.14.0
[107] highr_0.10 fastmap_1.1.1
[109] rlang_1.1.3 htmlwidgets_1.6.4
[111] shiny_1.8.0 farver_2.1.1
[113] jquerylib_0.1.4 zoo_1.8-12
[115] jsonlite_1.8.8 RCurl_1.98-1.14
[117] magrittr_2.0.3 GenomeInfoDbData_1.2.11
[119] dotCall64_1.1-1 munsell_0.5.0
[121] Rcpp_1.0.12 viridis_0.6.5
[123] reticulate_1.35.0 stringi_1.8.3
[125] zlibbioc_1.48.0 MASS_7.3-60.0.1
[127] plyr_1.8.9 parallel_4.3.2
[129] listenv_0.9.1 ggrepel_0.9.5
[131] deldir_2.0-2 Biostrings_2.70.2
[133] graphlayouts_1.1.0 splines_4.3.2
[135] tensor_1.5 hms_1.1.3
[137] locfit_1.5-9.8 ps_1.7.6
[139] igraph_2.0.2 spatstat.geom_3.2-8
[141] RcppHNSW_0.6.0 reshape2_1.4.4
[143] evaluate_0.23 BiocManager_1.30.22
[145] tzdb_0.4.0 tweenr_2.0.3
[147] httpuv_1.6.14 RANN_2.6.1
[149] polyclip_1.10-6 future_1.33.1
[151] scattermore_1.2 ggforce_0.4.2
[153] xtable_1.8-4 RSpectra_0.16-1
[155] later_1.3.2 viridisLite_0.4.2
[157] memoise_2.0.1 cluster_2.1.6
[159] timechange_0.3.0 globals_0.16.2